



SiliconCloud, Production Ready
Cloud with Low Cost
Teaming up with excellent open-source foundation models.
SiliconCloud, Production Ready
Cloud with Low Cost
Teaming up with excellent open-source foundation models.
Top-quality model services
01.
Chat
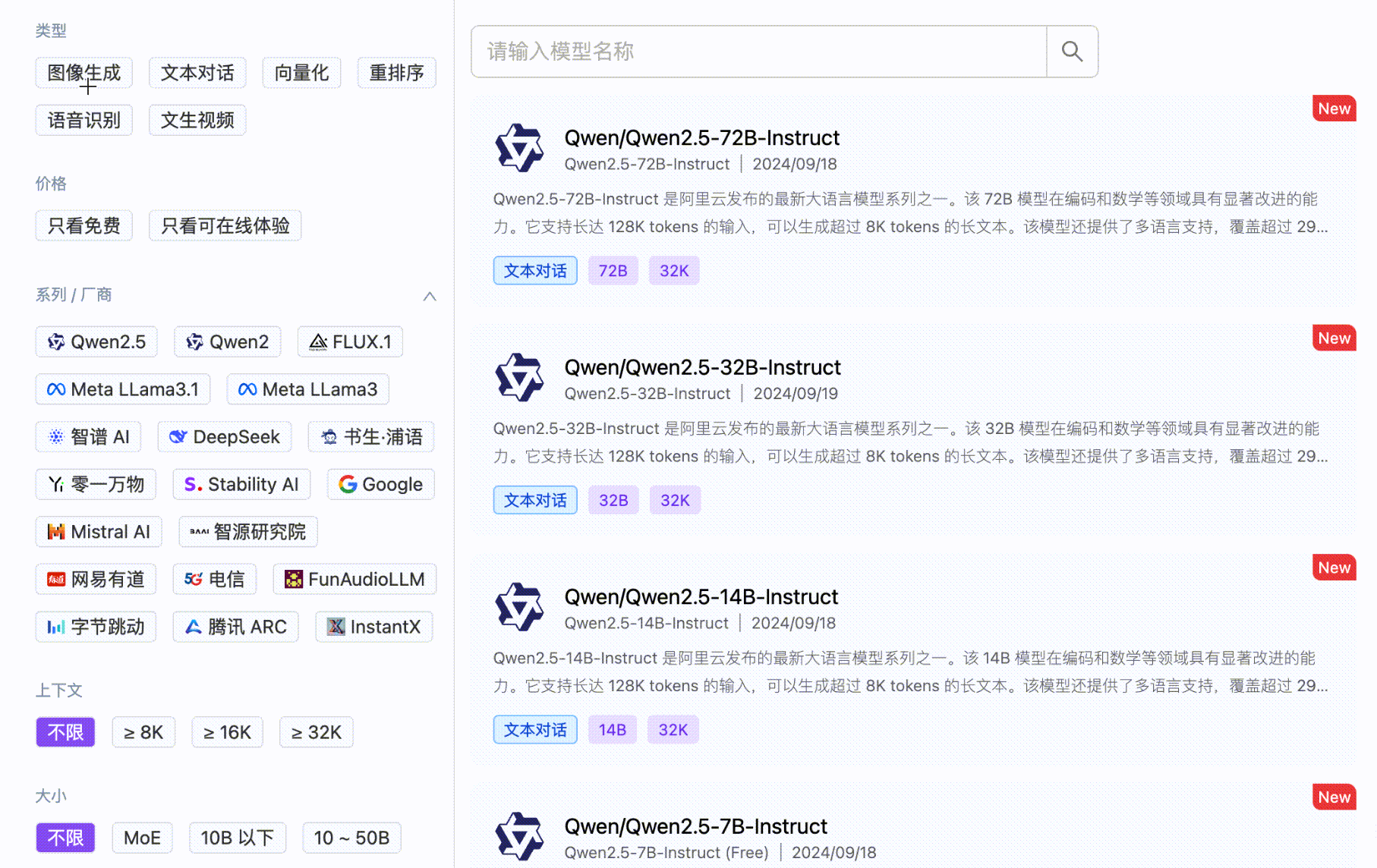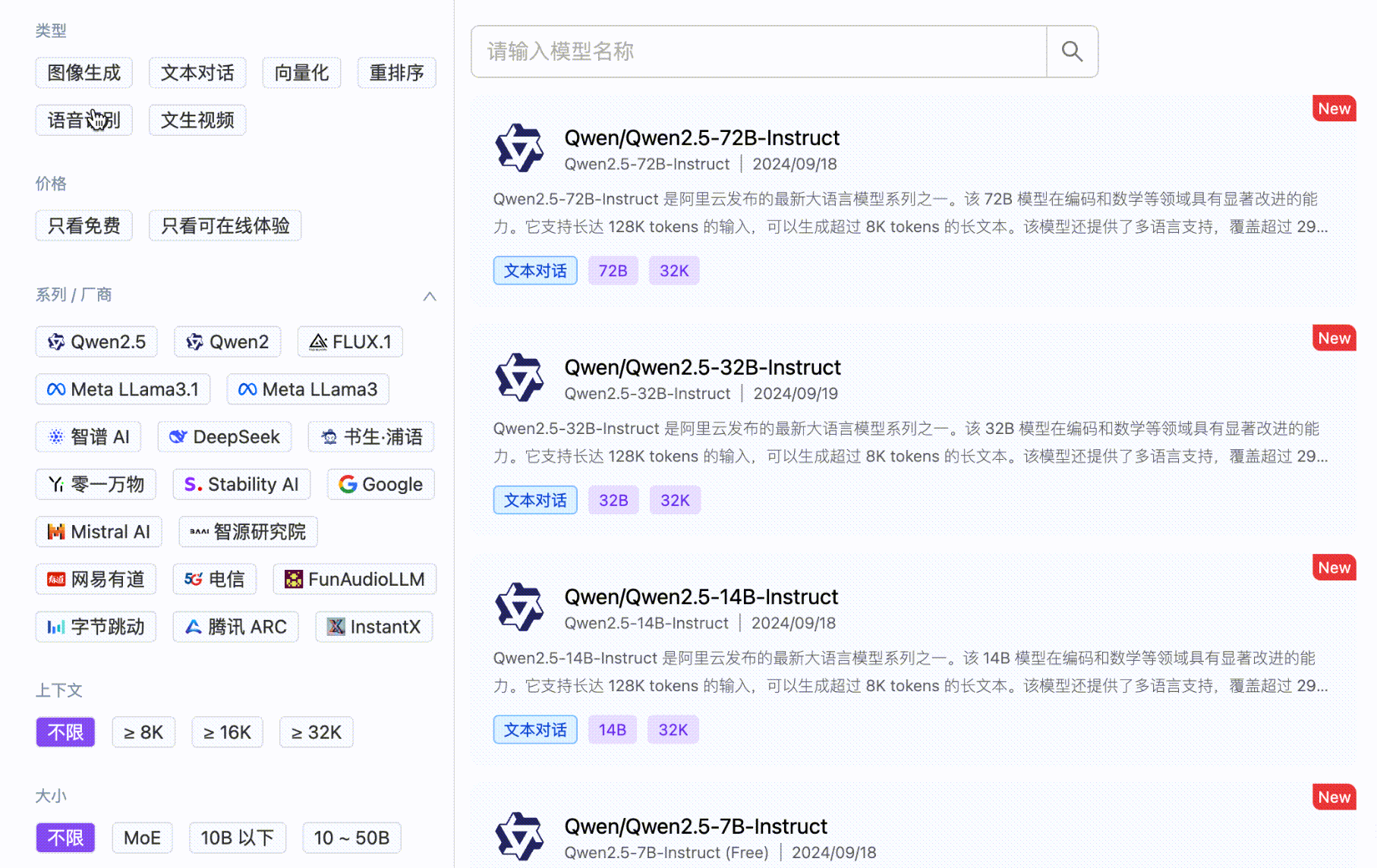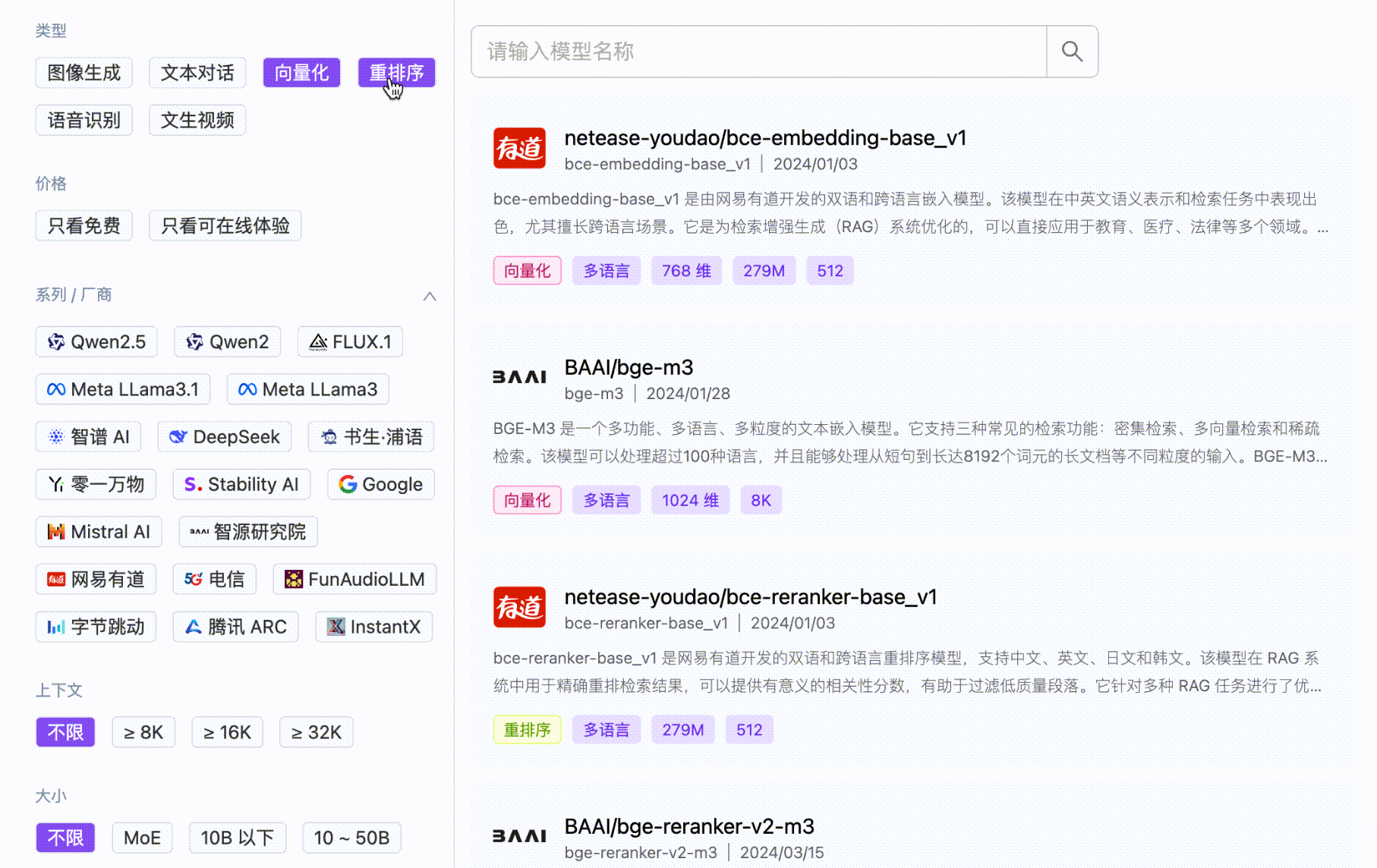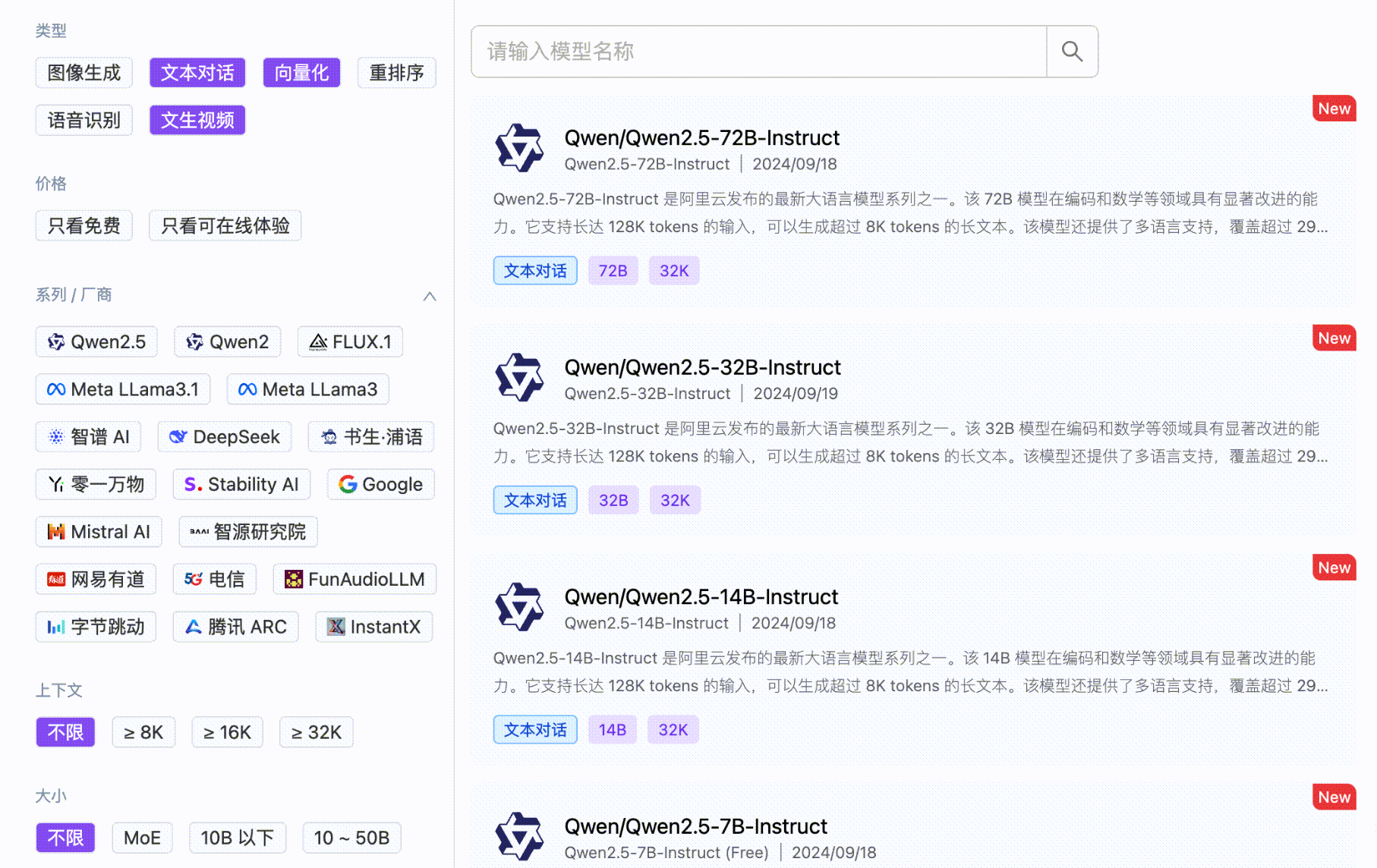
SiliconCloud delivers efficient, user-friendly, and scalable LLM models, with an out-of-the-box inference acceleration capability, including Qwen、DeepSeek、 GLM4, etc.
02.
Image
SiliconCloud encompasses a diverse range of text-to-image and text-to-video models, such as Kolors.
03.
More
SiliconCloud also offers other efficient and feature-rich model categories, including embedding, reranker, voice, and video generation models.
01.
Chat
SiliconCloud delivers efficient, user-friendly, and scalable LLM models, with an out-of-the-box inference acceleration capability, including Qwen、DeepSeek、 GLM4, etc.
02.
Image
SiliconCloud encompasses a diverse range of text-to-image and text-to-video models, such as Kolors.
03.
More
SiliconCloud also offers other efficient and feature-rich model categories, including embedding, reranker, voice, and video generation models.
Cloud inference services based on excellent open-source models.
MaaS
Enterprise-level all-scenario model service
Enterprise-level all-scenario model service
MaaS
MaaS
Cloud inference services based on excellent open-source models.
Cloud inference services based on excellent open-source models.
01.
Chat
SiliconCloud delivers efficient, user-friendly, and scalable LLM models, with an out-of-the-box inference acceleration capability, including Qwen、DeepSeek、 GLM4, etc.
02.
Image
03.
More
01.
Chat
SiliconCloud delivers efficient, user-friendly, and scalable LLM models, with an out-of-the-box inference acceleration capability, including Qwen、DeepSeek、 GLM4, etc.
02.
Image
03.
More
Model Fine-Tune and Deploying
Model Fine-Tune and Deploying
Model Fine-Tune and Deploying
designed for large-scale model fine-tuning and deploying. Through the platform, users can quickly and seamlessly deploy custom models as services and fine-tune them based on the data uploaded.
designed for large-scale model fine-tuning and deploying. Through the platform, users can quickly and seamlessly deploy custom models as services and fine-tune them based on the data uploaded.
designed for large-scale model fine-tuning and deploying. Through the platform, users can quickly and seamlessly deploy custom models as services and fine-tune them based on the data uploaded.
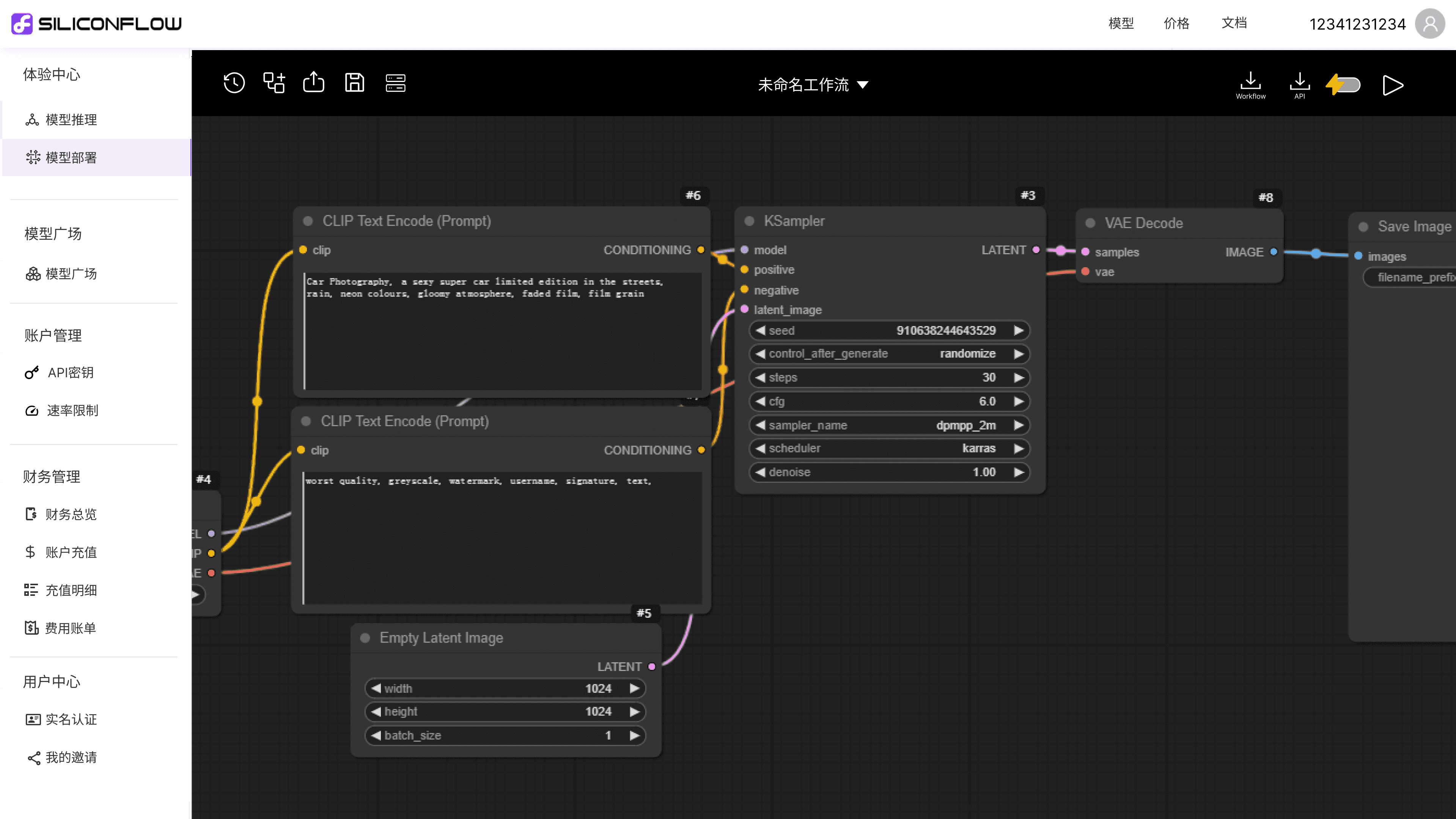
Data Upload
Build a suitable dataset and upload it for creating fine-tuning jobs. The data set consists of a single JSONL file, where each line is a separate training data.
Step.01→
Fine-tuning
Select the appropriate dataset and adjust the relevant parameters to improve the model effect and meet the customization needs.
Step.02→
Effect Evaluation
Upload the evaluation dataset. Evaluate the effect of the trained model, and choose tge best one for deployment.
Step.03→
Model Deploying
Deploy the fine-tuned model on the cloud platform and call it through APIs.
Step.04
One-Stop: From Fine-Tune to Deploying
One-Stop: From Fine-Tune to Deploying
Data Upload
Build a suitable dataset and upload it for creating fine-tuning jobs. The data set consists of a single JSONL file, where each line is a separate training data.
Step.01→
Fine-tuning
Select the appropriate dataset and adjust the relevant parameters to improve the model effect and meet the customization needs.
Step.02→
Effect Evaluation
Upload the evaluation dataset. Evaluate the effect of the trained model, and choose tge best one for deployment.
Step.03→
Model Deploying
Deploy the fine-tuned model on the cloud platform and call it through APIs.
Step.04
One-Stop: From Fine-Tune to Deploying
Data Upload
Build a suitable dataset and upload it for creating fine-tuning jobs. The data set consists of a single JSONL file, where each line is a separate training data.
Step.01→
Fine-tuning
Select the appropriate dataset and adjust the relevant parameters to improve the model effect and meet the customization needs.
Step.02→
Effect Evaluation
Upload the evaluation dataset. Evaluate the effect of the trained model, and choose tge best one for deployment.
Step.03→
Model Deploying
Deploy the fine-tuned model on the cloud platform and call it through APIs.
Step.04

High performance, flexible, and ease to use
High performance, flexible, and ease to use
High performance, flexible, and ease to use
Blazing fsat model inference
Blazing fsat model inference
Blazing fsat model inference
Time latency of LLM is reduced by up to 2.7 times
Time latency of LLM is reduced by up to 2.7 times
Time latency of LLM is reduced by up to 2.7 times
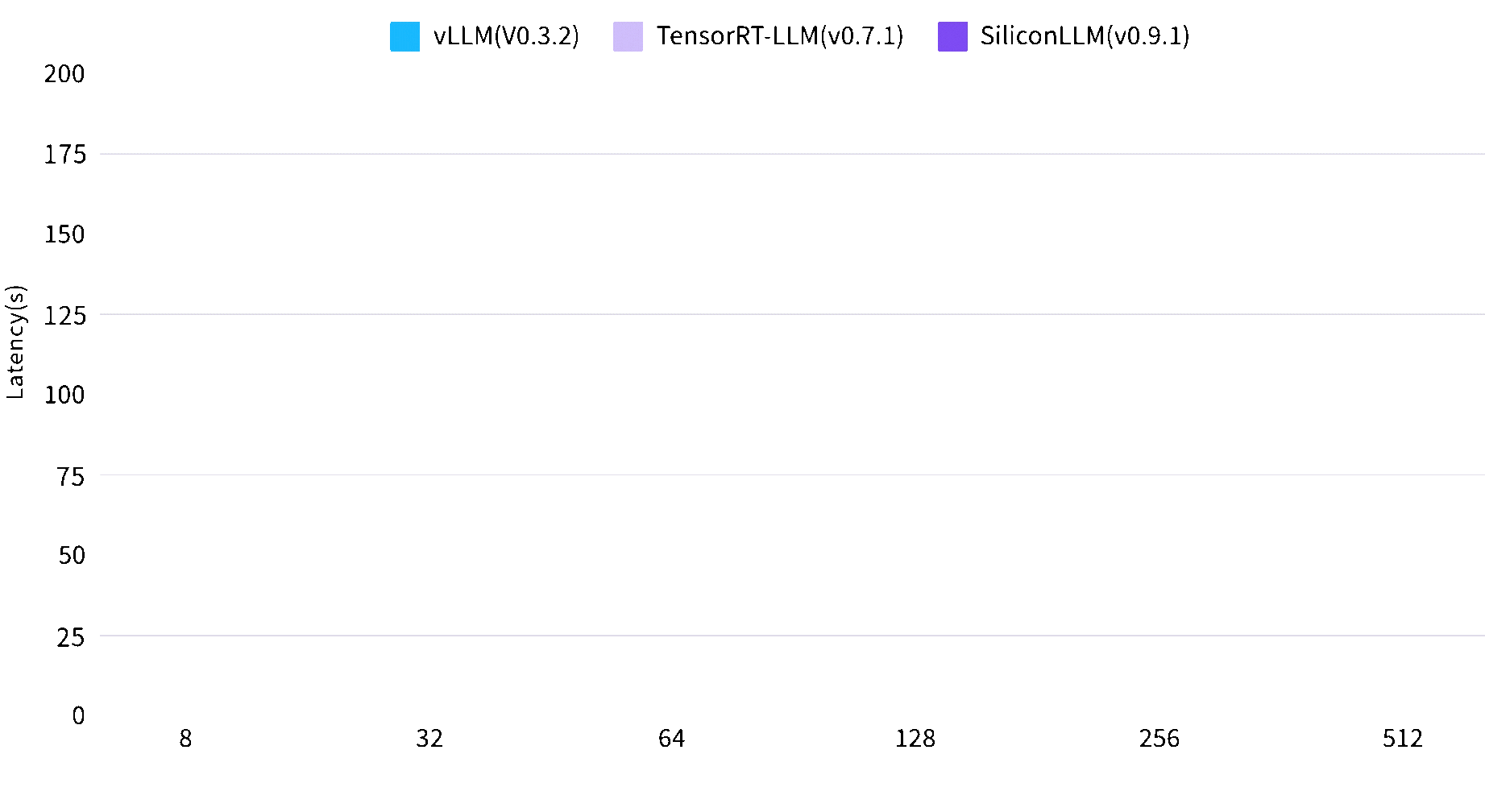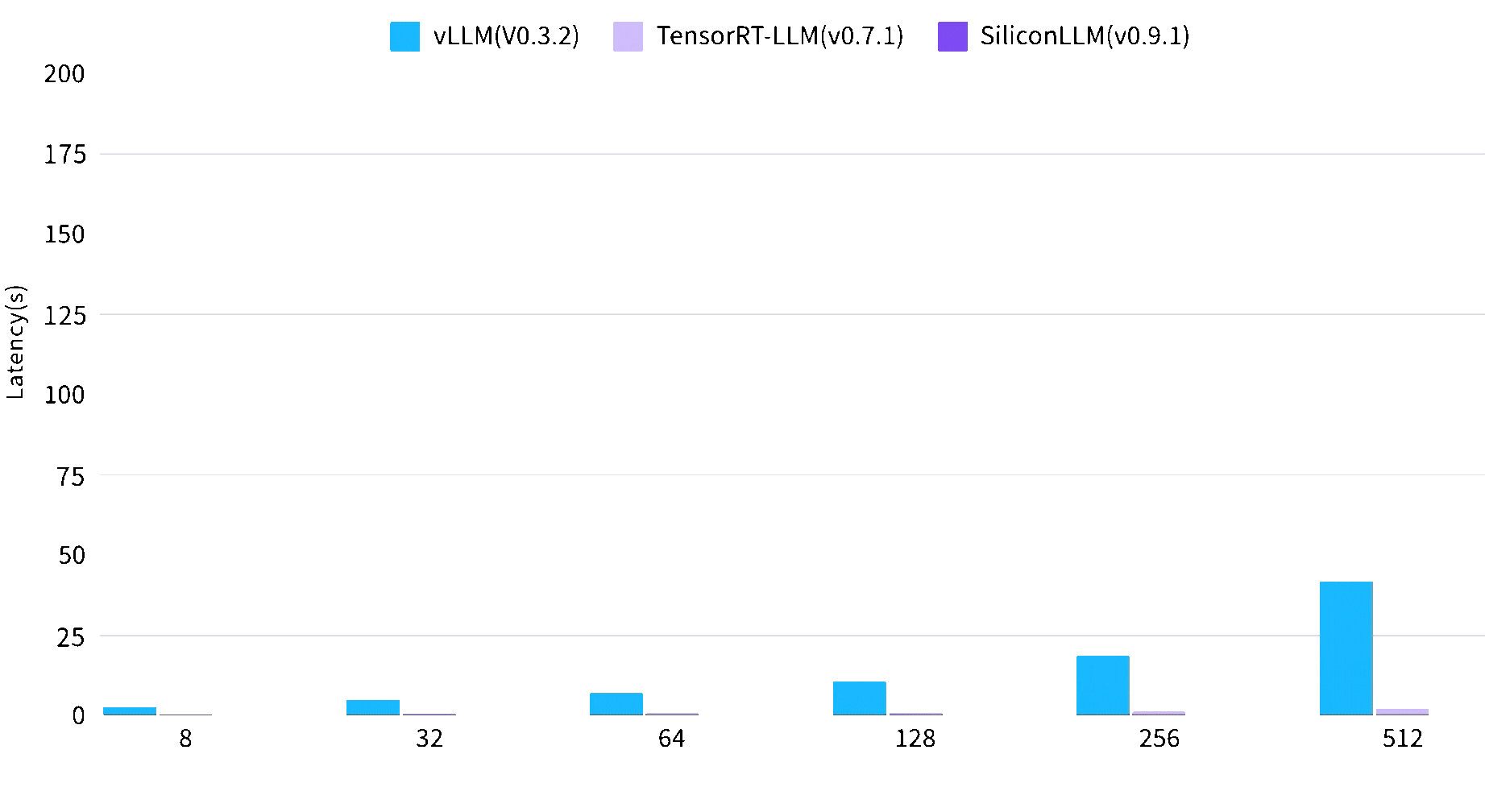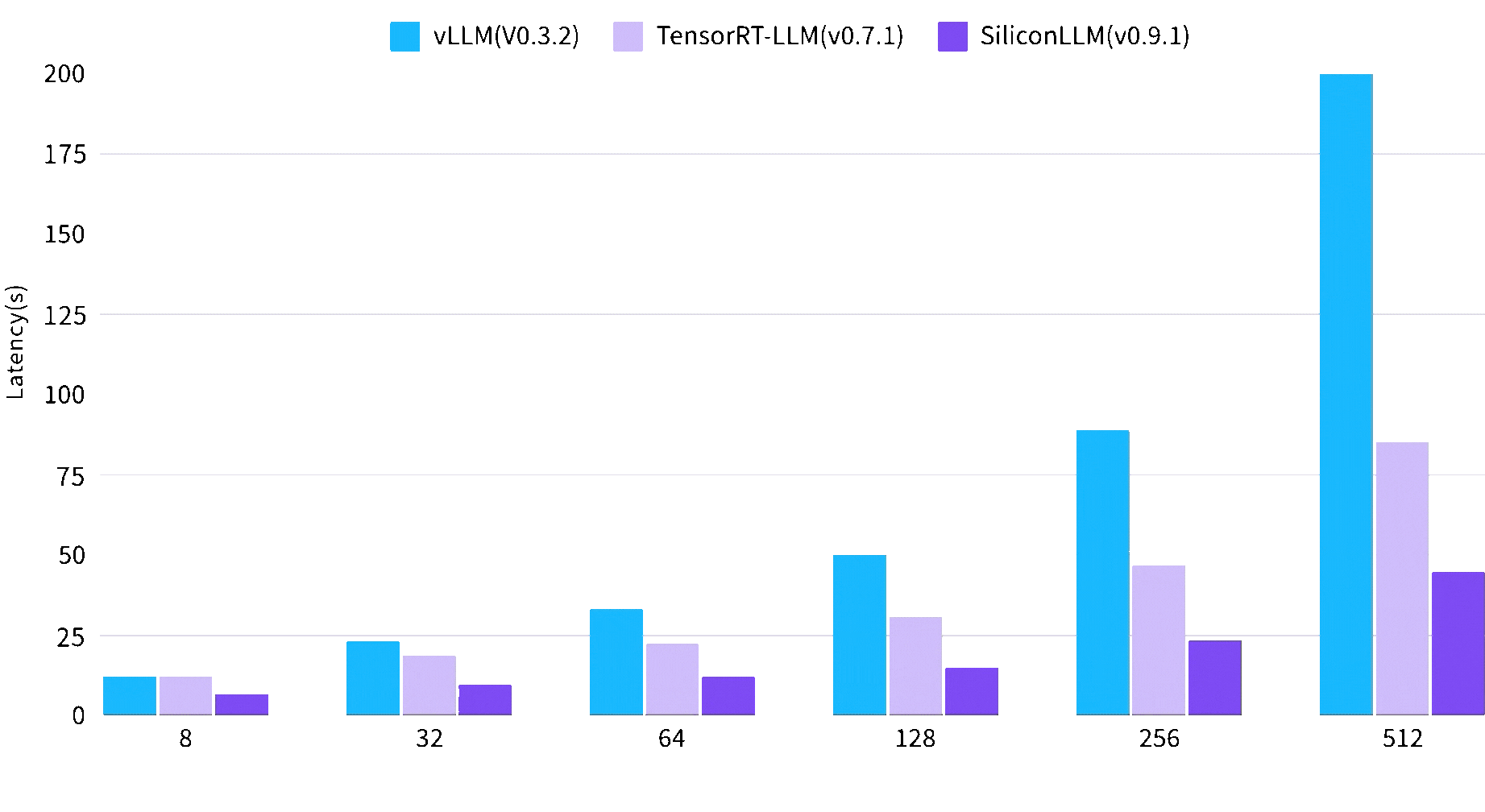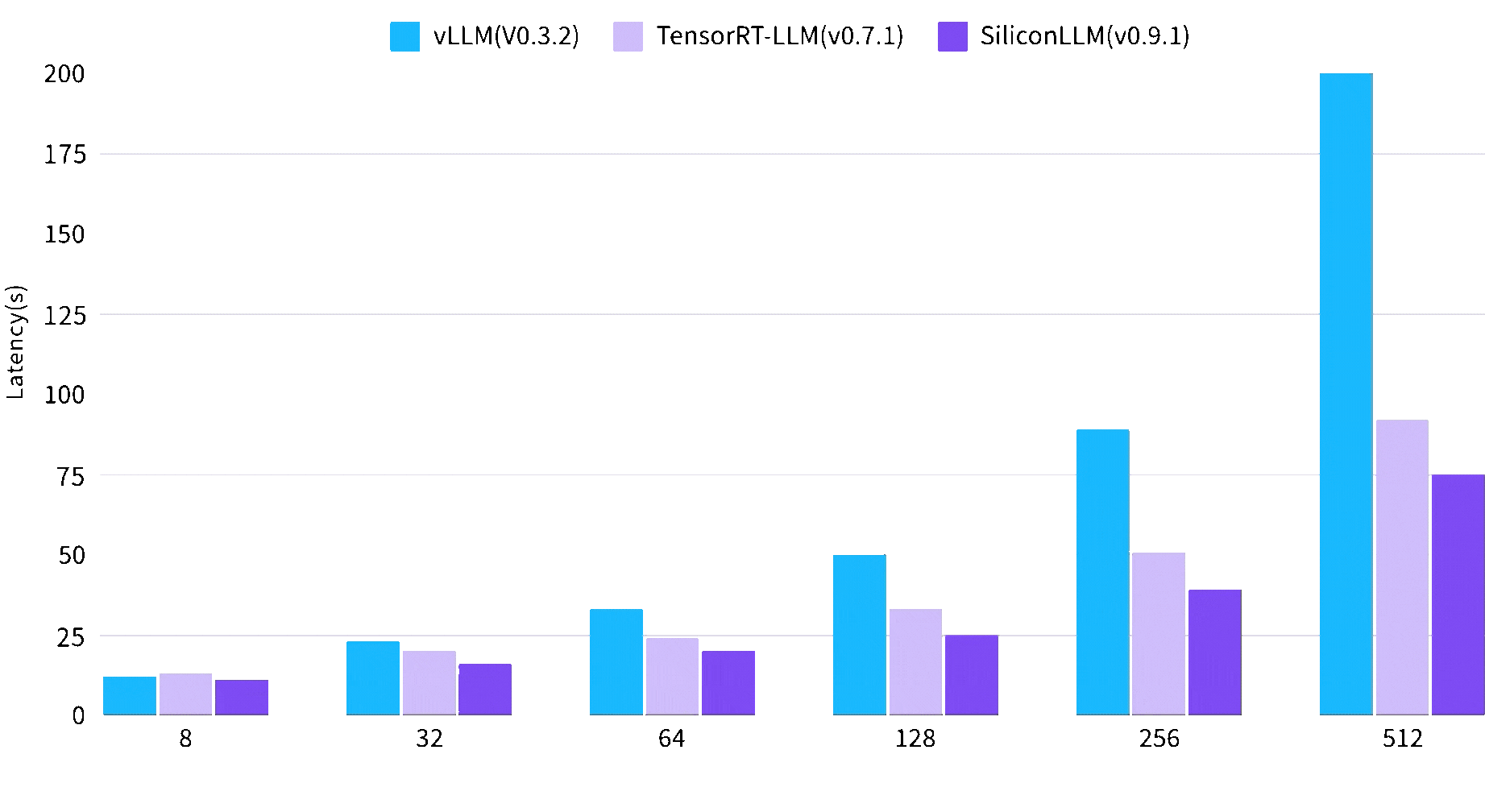
Max Concurrent Requsets
Max Concurrent Requsets
Max Concurrent Requsets
Speed of text to image is increased by 3 times
Speed of text to image is increased by 3 times
Speed of text to image is increased by 3 times
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
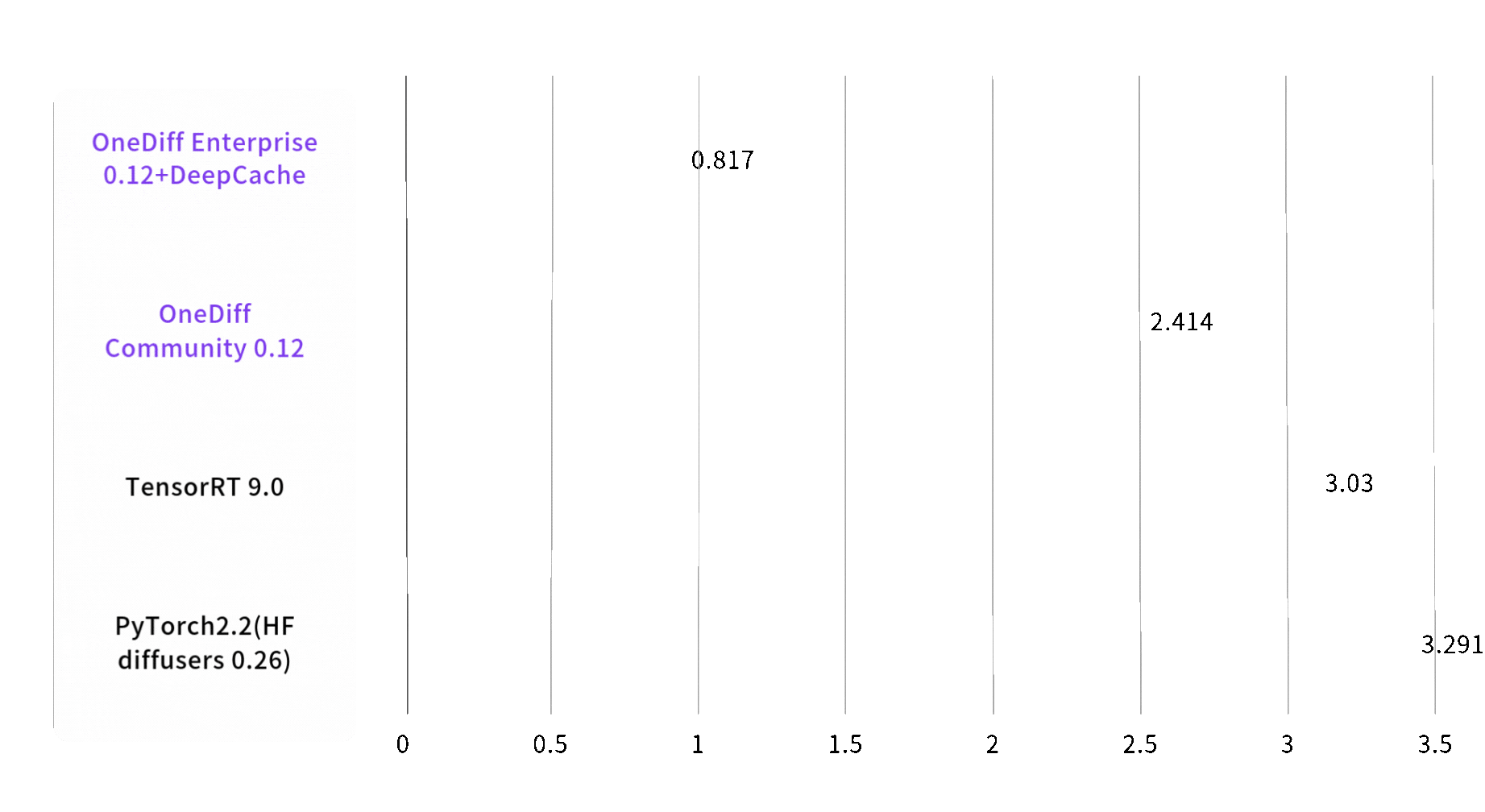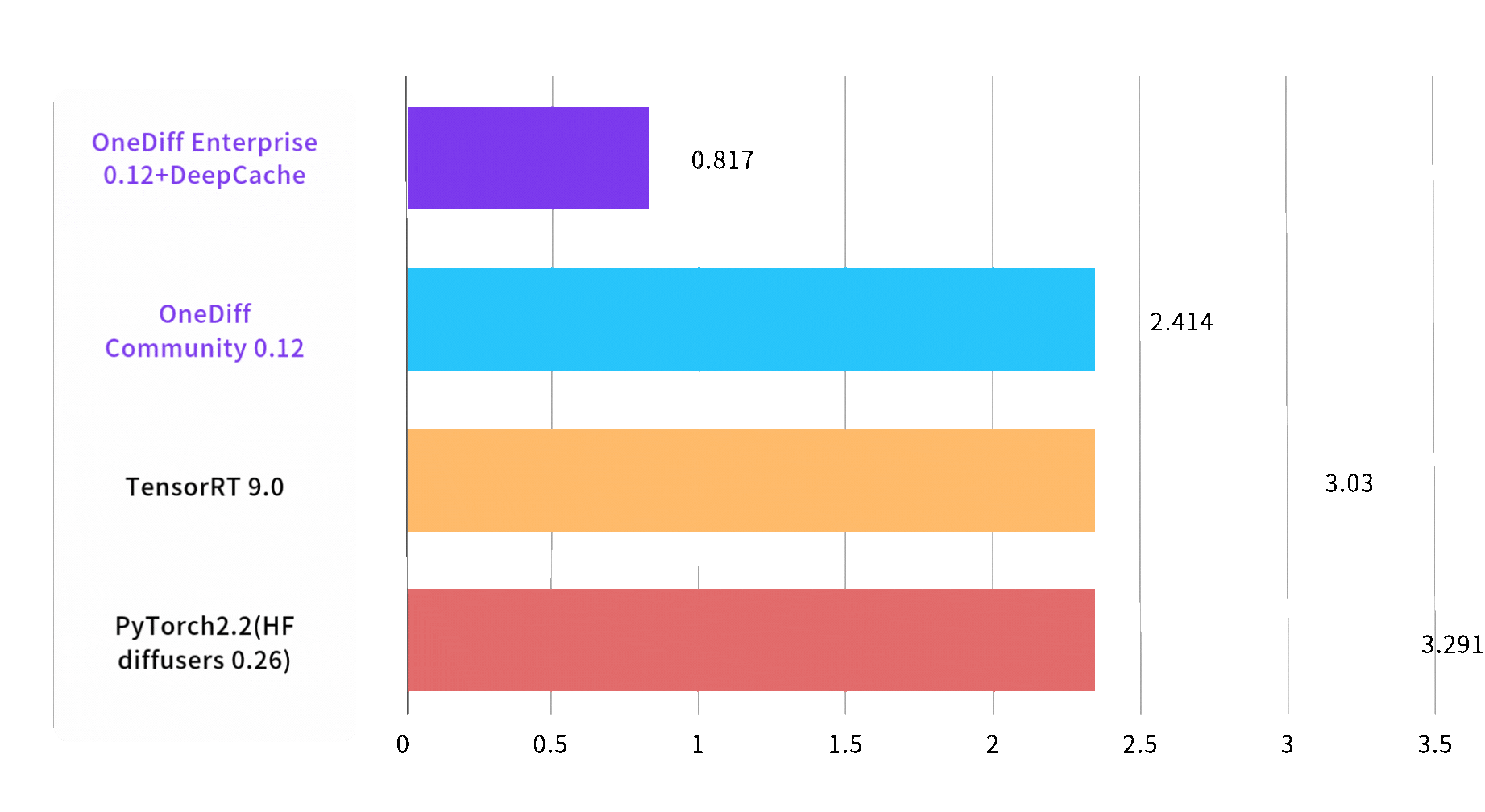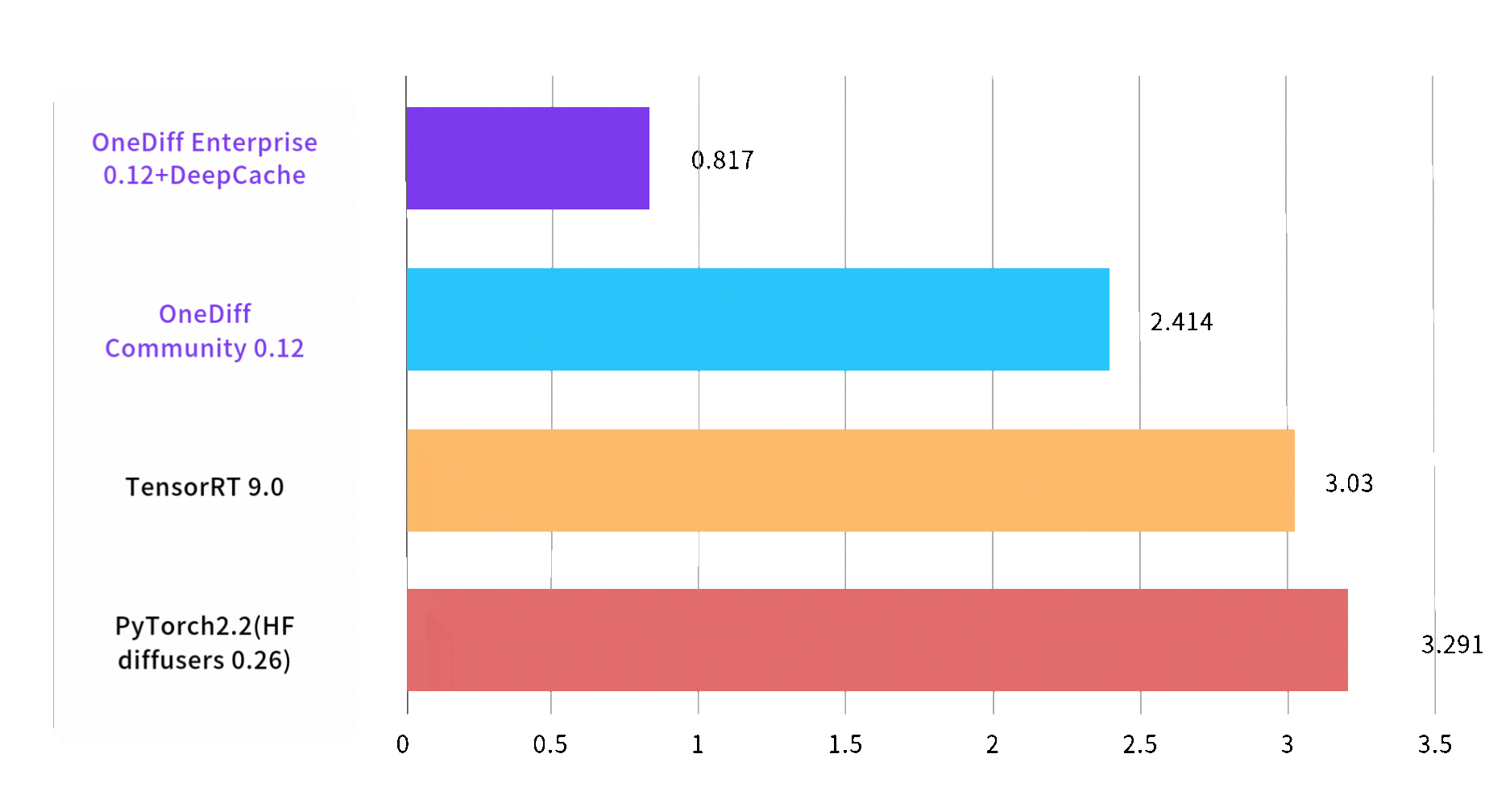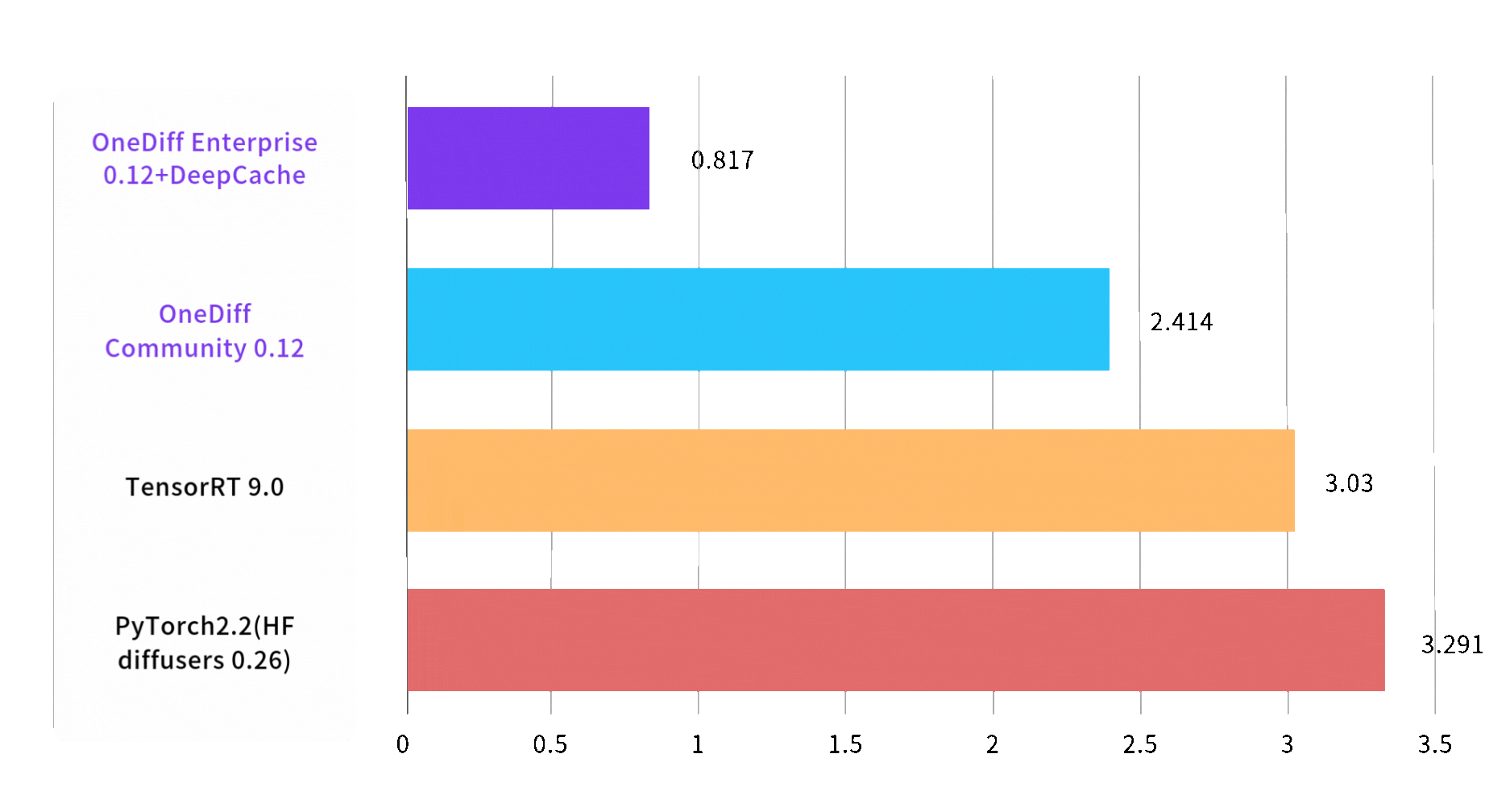
End2End Time (sec)
End2End Time (sec)
End2End Time (sec)
Auto-scaling on demand
Auto-scaling on demand
Auto-scaling on demand
1.
1.
Create an auto-scaling group which contains a collection of SiliconCloud instances.
Create an auto-scaling group which contains a collection of SiliconCloud instances.
1.
Create an auto-scaling group which contains a collection of SiliconCloud instances.
3.
Specify minimum and maximum numbers of instance in that group.
2.
Specify desired capacity and auto-scaling policies.
2.
4.
2.
Specify desired capacity and auto-scaling policies.
Specify desired capacity and auto-scaling policies.
Created successfully. The platform will automatically scales the service on demand.
3.
3.
Specify minimum and maximum numbers of instance in that group.
Specify minimum and maximum numbers of instance in that group.
4.
4.
Created successfully. The platform will automatically scales the service on demand.
Created successfully. The platform will automatically scales the service on demand.

Easy to use
Easy to use
Easy to use
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
Model Inference
With just a few lines of code, developers can quickly use SiliconCloud's rapid mockup service.
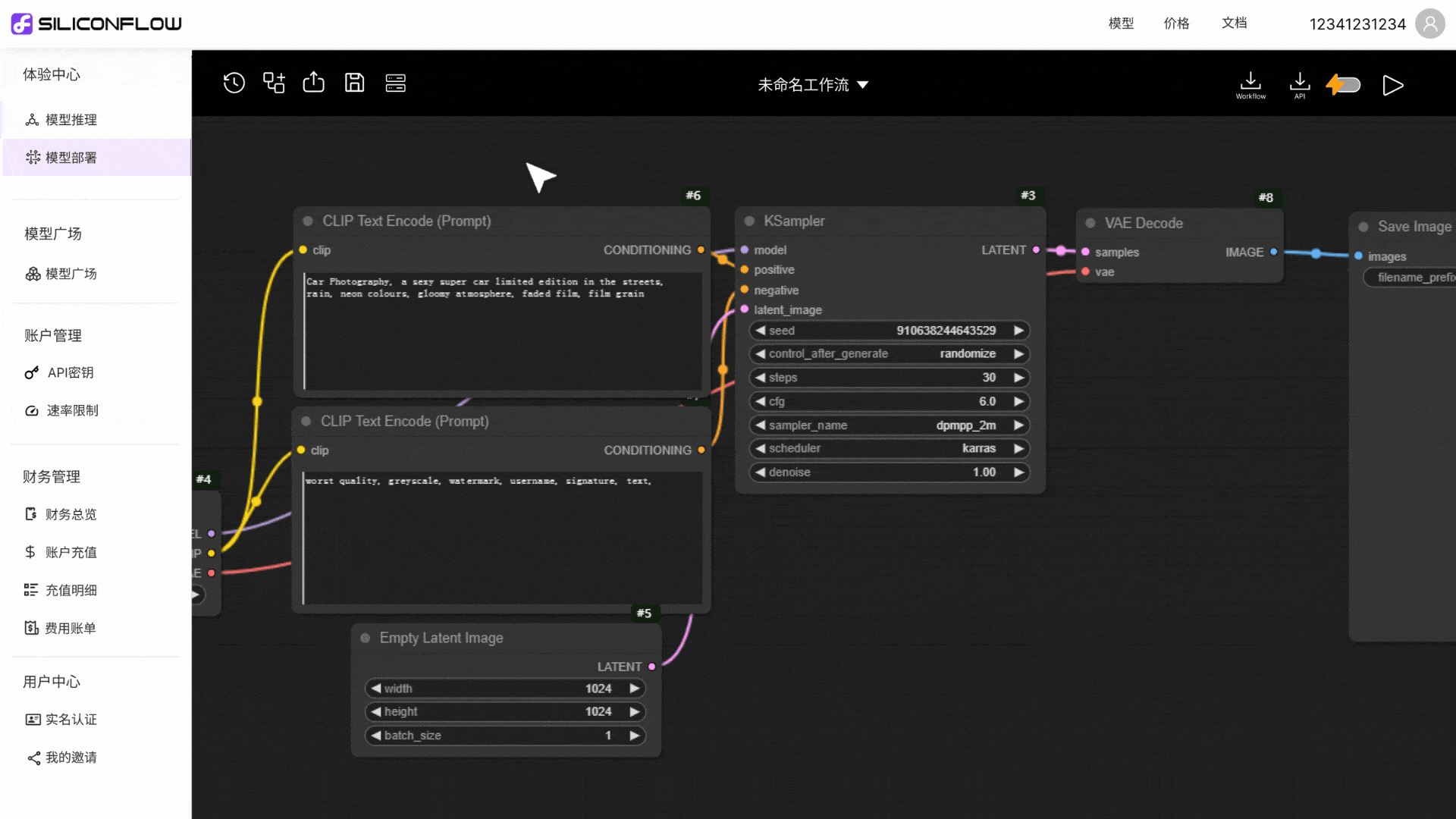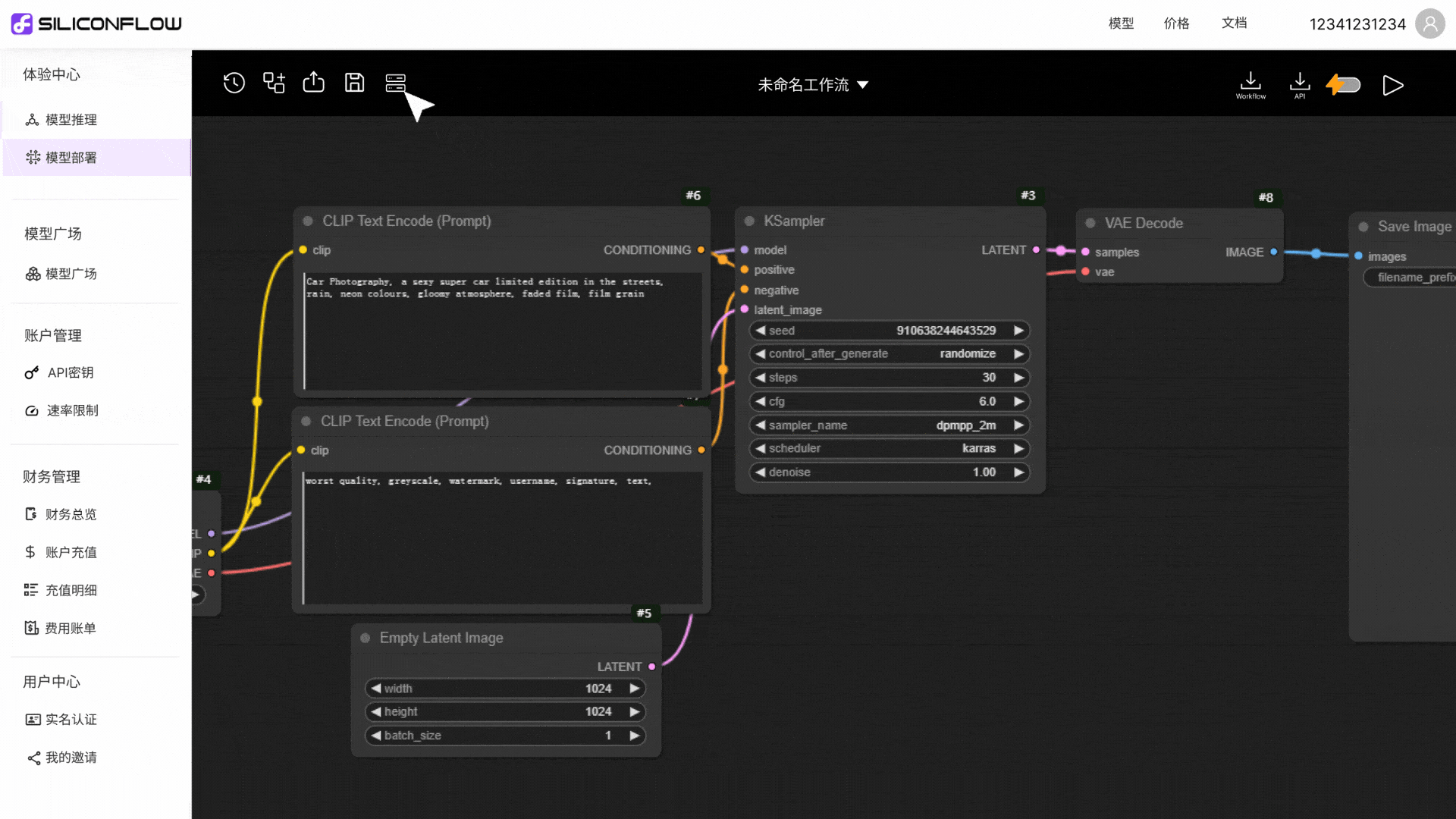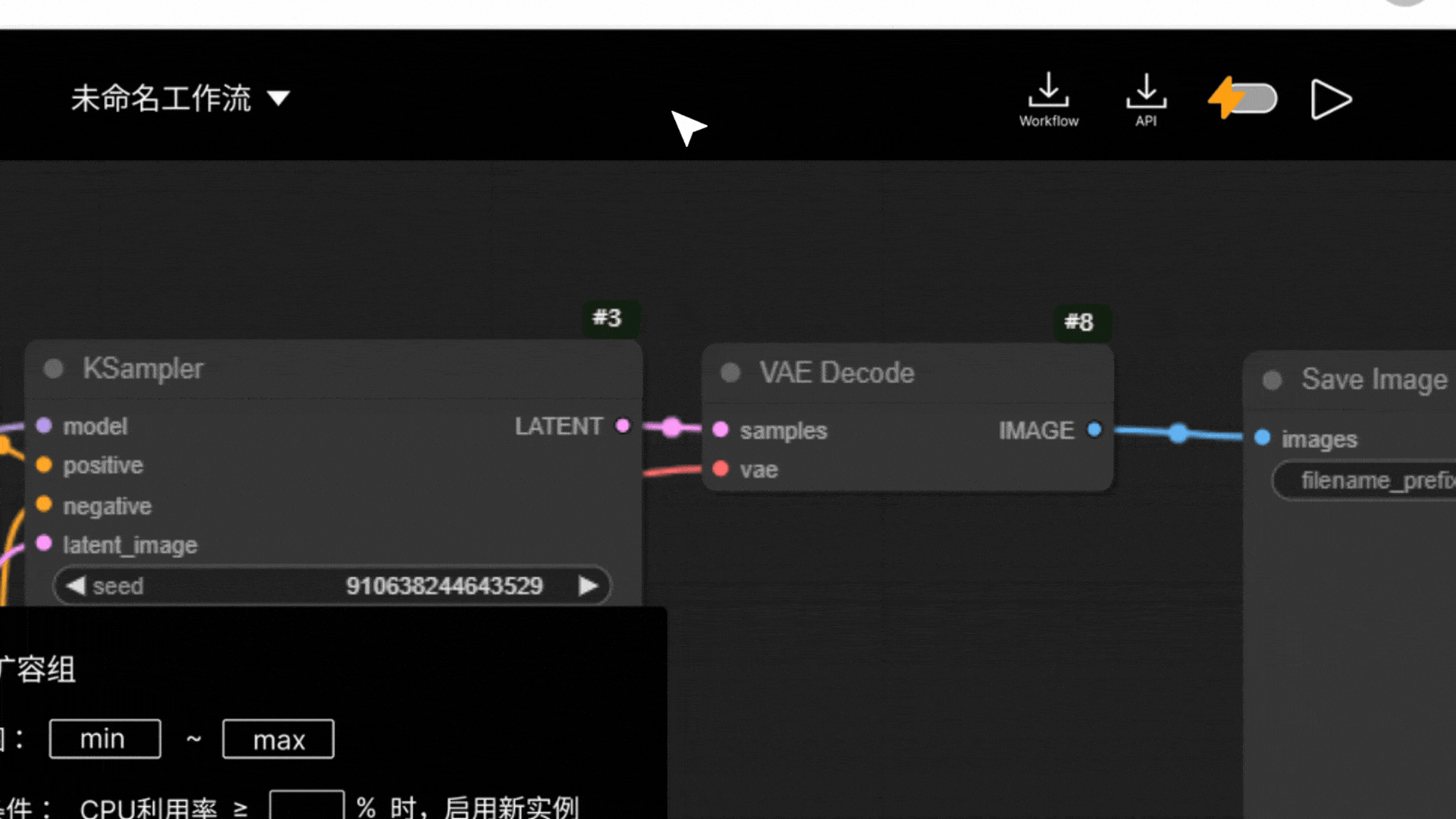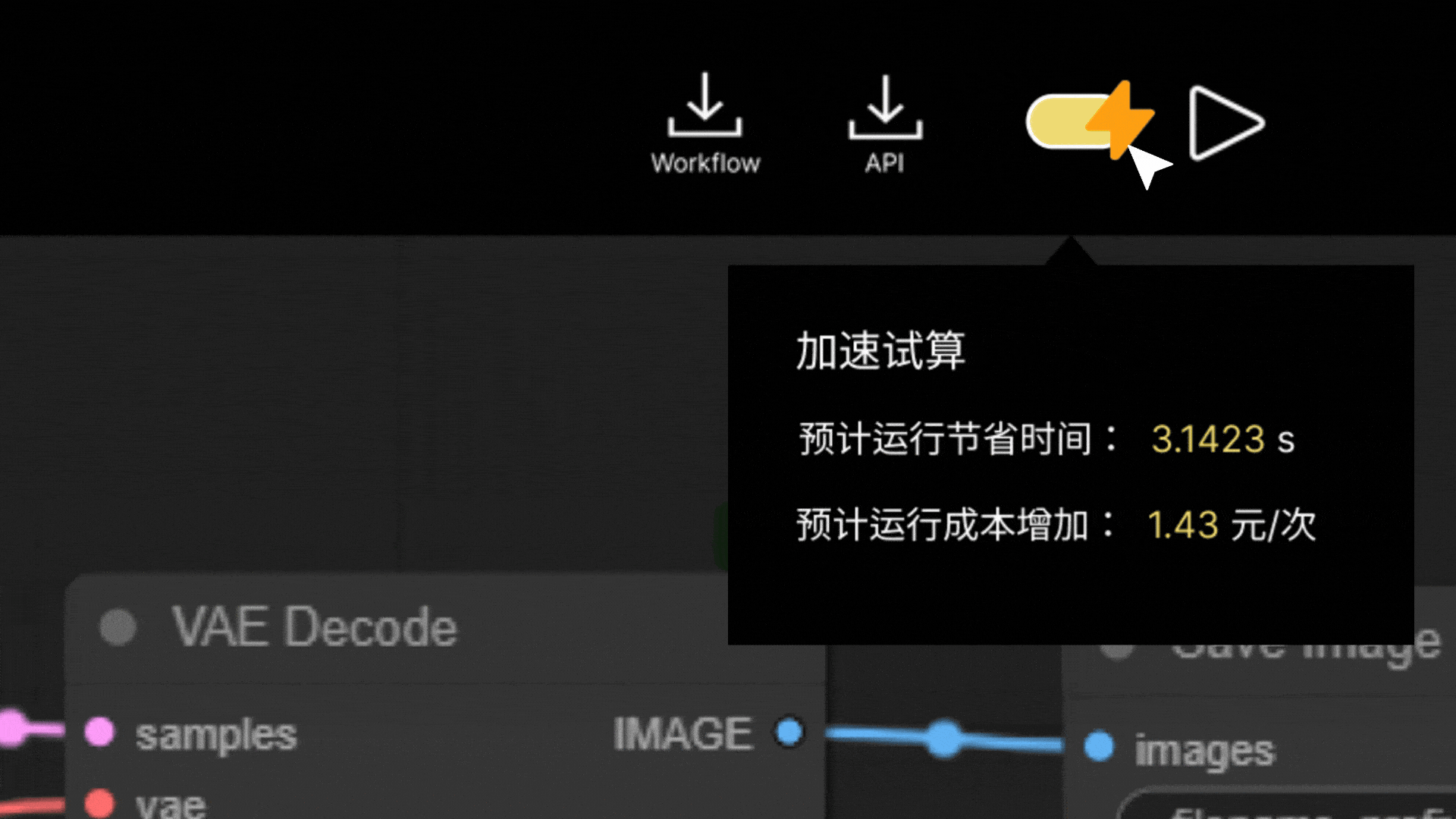
Model Deploy
·
Upload your workflow and Download the callable Model Service API.
·
Reduce the chances of application downtime with auto scaling.
·
Accelerate your workflow as needed.
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
Model Inference
Model Inference
With just a few lines of code, developers can quickly use SiliconCloud's rapid mockup service.
With just a few lines of code, developers can quickly use SiliconCloud's rapid mockup service.
Model Deploy
Model Deploy
·
Upload your workflow and Download the callable Model Service API.
Upload your workflow and Download the callable Model Service API.
·
Reduce the chances of application downtime with auto scaling.
Reduce the chances of application downtime with auto scaling.
·
Accelerate your workflow as needed.
Accelerate your workflow as needed.
Service Mode
Serverless Deployment
Built for developers
High-performance inference, industry-leading speed
Diverse models, covering multiple scenarios
Pay-as-you-go, per-token pricing
Serverless rate limits
On-demand Deployment
Enhanced for start-ups
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Reserved Capacity
Enhanced for advanced enterprises
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Competitive Unit Pricing
Prioritize using the latest product features
Service Mode
Serverless Deployment
Built for developers
High-performance inference, industry-leading speed
Diverse models, covering multiple scenarios
Pay-as-you-go, per-token pricing
Serverless rate limits
On-demand Deployment
Enhanced for start-ups
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Reserved Capacity
Enhanced for advanced enterprises
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Competitive Unit Pricing
Prioritize using the latest product features
Service Mode
Serverless Deployment
Built for developers
High-performance inference, industry-leading speed
Diverse models, covering multiple scenarios
Pay-as-you-go, per-token pricing
Serverless rate limits
On-demand Deployment
Enhanced for start-ups
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Reserved Capacity
Enhanced for advanced enterprises
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Competitive Unit Pricing
Prioritize using the latest product features
Service Mode
Serverless Deployment
Built for developers
High-performance inference, industry-leading speed
Diverse models, covering multiple scenarios
Pay-as-you-go, per-token pricing
Serverless rate limits
On-demand Deployment
Enhanced for start-ups
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Reserved Capacity
Enhanced for advanced enterprises
Custom models tailored to your needs
Configurable strategies optimization
Isolated resources for high QoS
Custom enterprise rate limiting
Competitive Unit Pricing
Prioritize using the latest product features
Accelerate AGI to Benefit Humanity



Accelerate AGI to Benefit Humanity
OneDiff, High-performance
Image Generation Engine
Teaming up with excellent open-source foundation models.