


SiliconCloud
SiliconCloud
SiliconCloud
Fine-tuning
*SiliconCloud charges based on the total number of tokens in your fine-tuning dataset.
Fine-tuning
Fine-tuning
Model
Price
$5.9/M tokens
$0.5/M tokens
*SiliconCloud charges based on the total number of tokens in your fine-tuning dataset.
*SiliconCloud charges based on the total number of tokens in your fine-tuning dataset.
Deployment Service
Deployment Service
Serverless Deployment
Serverless Deployment
Model
Price
Base model
Fine-tuned model
price of corresponding base model*1.5
On-demand Deployment & Reserved Capacity
On-demand Deployment & Reserved Capacity
Prepaid Duration
Prepaid Duration
GPU Type
GPU Type*
Price
Price
Pay-as-you-go GPU instance
Compute Unit A
Compute Unit B
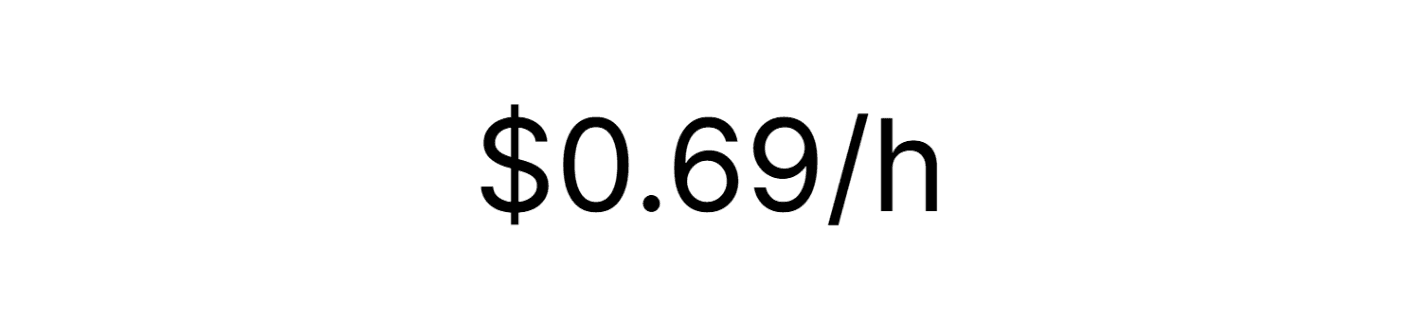
$0.35/h

Pay-as-you-go Inference Engine
Compute Unit A
Compute Unit B
$0.30/h
$0.23/h
$0.80/h
Reserved Capacity GPU instance
With Inference Engine
Compute Unit A
Compute Unit B
$0.20/h
Product
Product Type*
Price
Pay-as-you-go GPU instance
Compute Unit A
Compute Unit B
Pay-as-you-go Inference Engine
Compute Unit A
Compute Unit B
$0.30/h
$0.80/h
Reserved Capacity GPU instance
with Inference Engine
Compute Unit A
Compute Unit B
Multimodal
*Compute Unit A is lower cost, Comoute Unit B is lower latency.
*Compute Unit A is lower cost, Comoute Unit B is lower latency.
Software Subscription
Software
Price
OneDiff
/NVIDIA Hopper architecture GPUs
OneDiff
/Other GPUs
Software Subscription
Dedicated email support
Software
Price
OneDiff
/NVIDIA Hopper architecture GPUs
OneDiff
/Other GPUs
*The current product price is only limited to use outside mainland China.
Deployment Service
Serverless Deployment
*Compute Unit A is lower cost, Comoute Unit B is lower latency.
On-demand Deployment
Prepaid Duration
GPU Type*
Price
Pay-as-you-go GPU instance
Compute Unit A
Compute Unit B
Pay-as-you-go Inference Engine
Compute Unit A
Compute Unit B
$0.30/h
$0.80/h
Reserved Capacity GPU instance
and Accleration Framework
Compute Unit A
Compute Unit B
Multimodal
Dedicated email support
Software Subscription
Software
Price
OneDiff
/NVIDIA Hopper architecture GPUs
OneDiff
/Other GPUs
*The current product price is only limited to use outside mainland China.
Frequently Asked Questions
Can I try SiliconCloud before subscribing?
Can I try OneDiff or SiliconLLM before subscribing?
Can I get a refund if I cancel my subscription before it expires?
Accelerate AGI to Benefit Humanity



Frequently Asked Questions
Can I try SiliconCloud before subscribing?
Can I try OneDiff or SiliconLLM before subscribing?
Can I get a refund if I cancel my subscription before it expires?
Can I try SiliconCloud before subscribing?
Can I try OneDiff or SiliconLLM before subscribing?
Can I get a refund if I cancel my subscription before it expires?
Frequently Asked Questions
Can I try SiliconCloud before subscribing?
Can I try OneDiff or SiliconLLM before subscribing?
Can I get a refund if I cancel my subscription before it expires?
Can I try SiliconCloud before subscribing?
Can I try OneDiff or SiliconLLM before subscribing?
Can I get a refund if I cancel my subscription before it expires?
Accelerate AGI to Benefit Humanity
Accelerate AGI to Benefit Humanity