



优质模型服务
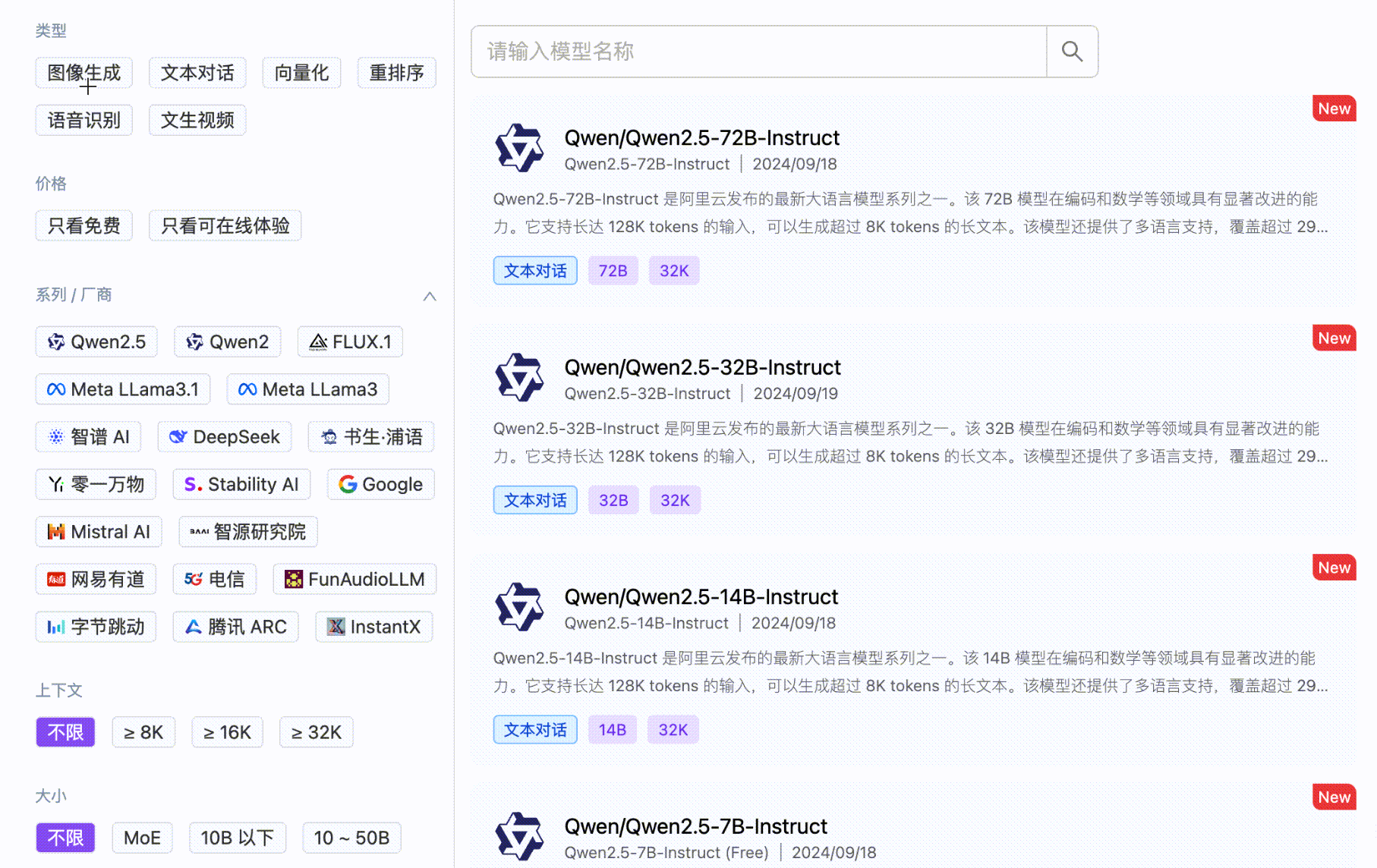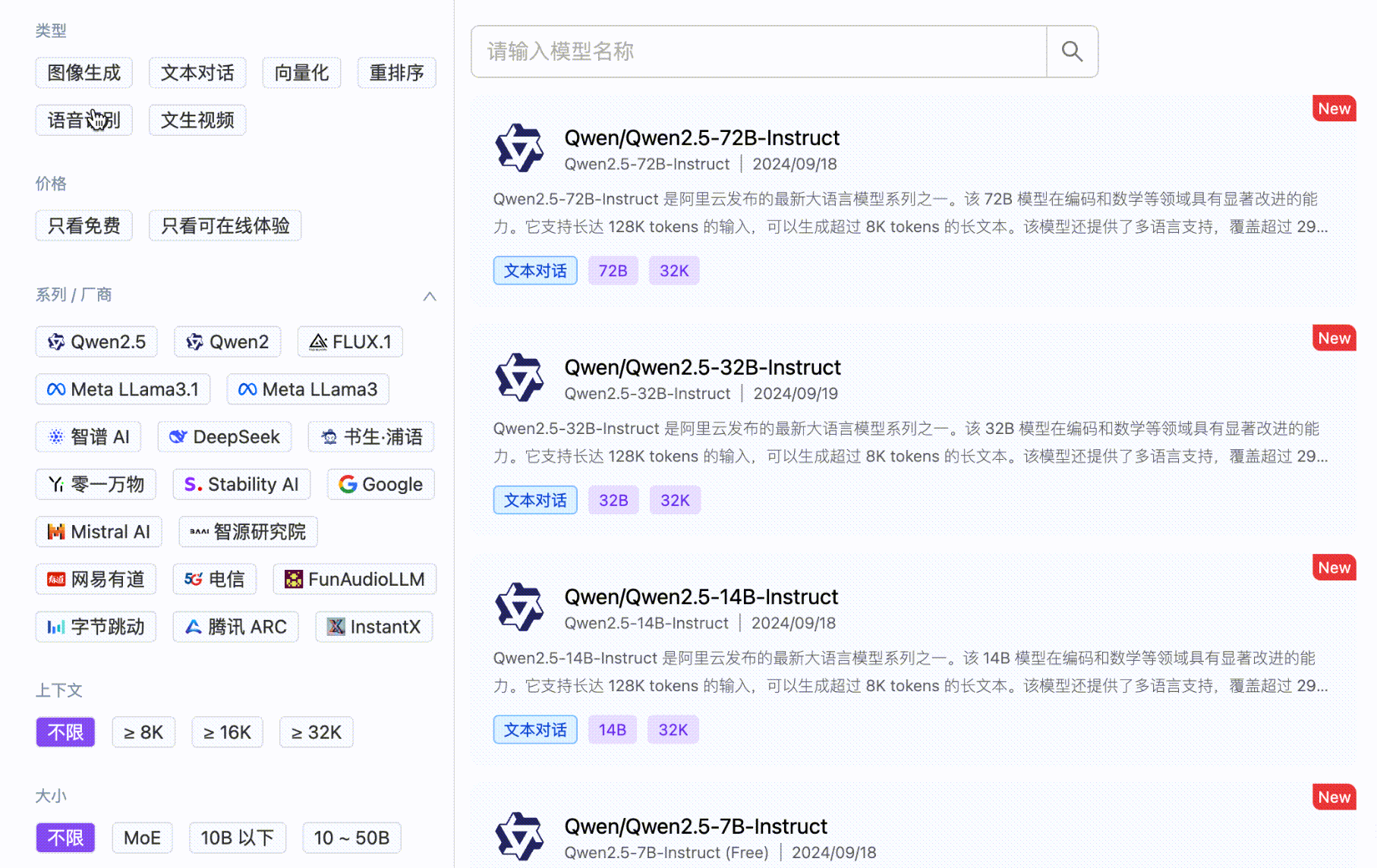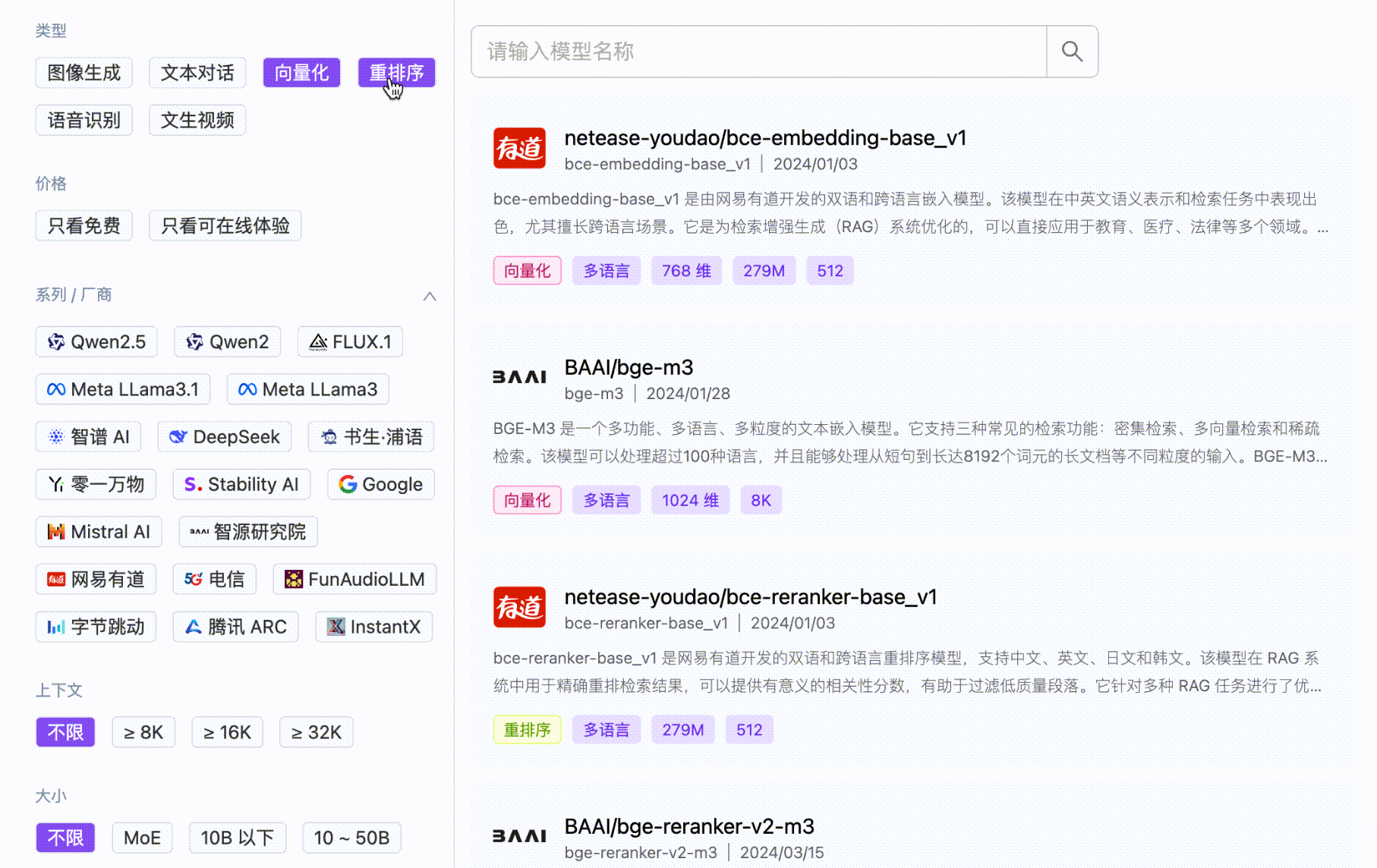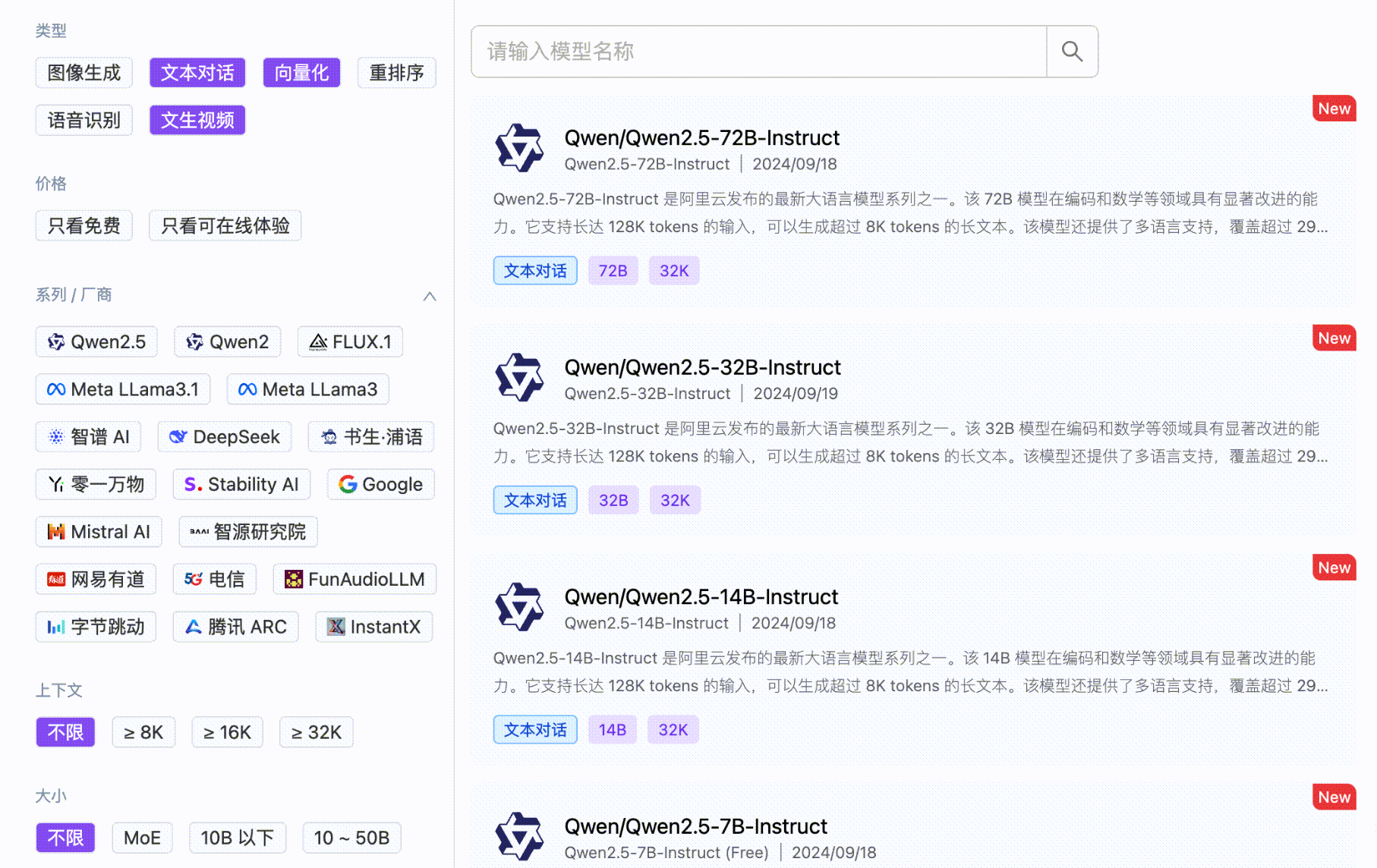
基于优秀开源模型的云端推理服务
MaaS
企业级全场景模型服务
企业级全场景模型服务
企业级模型微调与部署
企业级模型微调与部署
企业级模型微调与部署
专为大模型微调与托管打造的一站式服务平台。通过该平台,用户可以快速、无缝地将自定义模型部署为服务,并根据自己上传的数据进行模型微调。
专为大模型微调与托管打造的一站式服务平台。通过该平台,用户可以快速、无缝地将自定义模型部署为服务,并根据自己上传的数据进行模型微调。
专为大模型微调与托管打造的一站式服务平台。通过该平台,用户可以快速、无缝地将自定义模型部署为服务,并根据自己上传的数据进行模型微调。
数据上传
构建合适的数据集并上传,用于创建微调作业。数据集由单个JSONL文件组成,其中每行都是一个单独的训练数据。
Step.01→
模型微调
选择合适的数据集,调整相关参数,训练特定的模型以提高模型效果,满足定制化需求。
Step.02→
效果评估
上传评测数据集,对训练好的模型进行效果评估,选出效果最优的微调模型进行部署。
Step.03→
模型部署
在云平台上部署微调后的模型,通过API接口调用。
Step.04
模型微调到模型部署全链路支持
模型精调到模型部署全链路支持
数据上传
构建合适的数据集并上传,用于创建微调作业。数据集由单个JSONL文件组成,其中每行都是一个单独的训练数据。
Step.01→
模型精调
选择合适的数据集,调整相关参数,训练特定的模型以提高模型效果,满足定制化需求。
Step.02→
效果评估
上传评测数据集,对训练好的模型进行效果评估,选出效果最优的精调模型进行部署。
Step.03→
模型部署
在云平台上部署精调后的模型,通过API接口调用。
Step.04
模型微调到模型部署全链路支持
数据上传
构建合适的数据集并上传,用于创建微调作业。数据集由单个JSONL文件组成,其中每行都是一个单独的训练数据。
Step.01→
模型微调
选择合适的数据集,调整相关参数,训练特定的模型以提高模型效果,满足定制化需求。
Step.02→
效果评估
上传评测数据集,对训练好的模型进行效果评估,选出效果最优的微调模型进行部署。
Step.03→
模型部署
在云平台上部署微调后的模型,通过API接口调用。
Step.04

高性能、弹性、易用
高性能、弹性、易用
高性能、弹性、易用
引擎赋能,模型推理显著提速
引擎赋能,模型推理显著提速
引擎赋能,模型推理显著提速
大语言模型时间延迟最高降低2.7倍
大语言模型时间延迟最高降低2.7倍
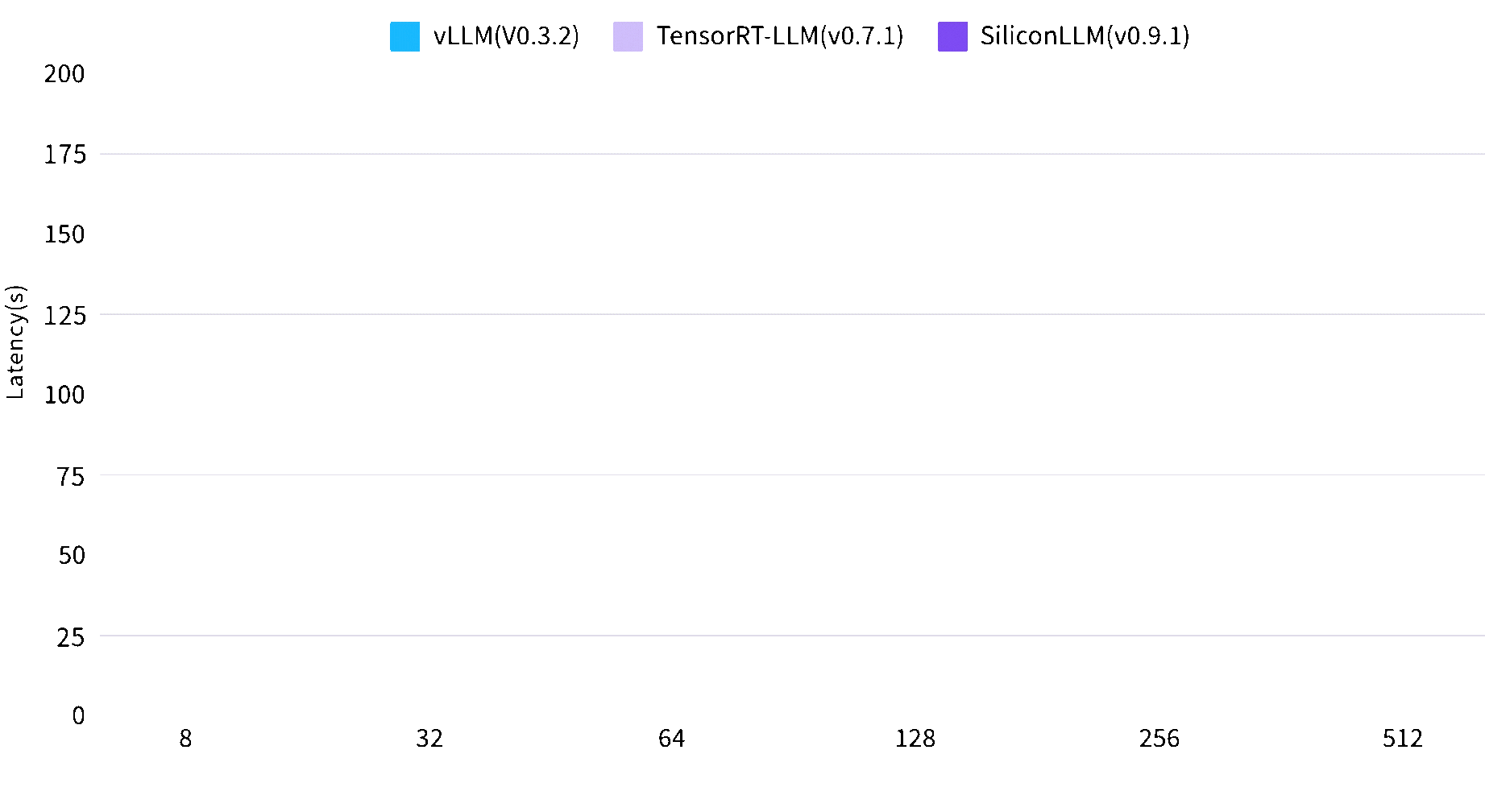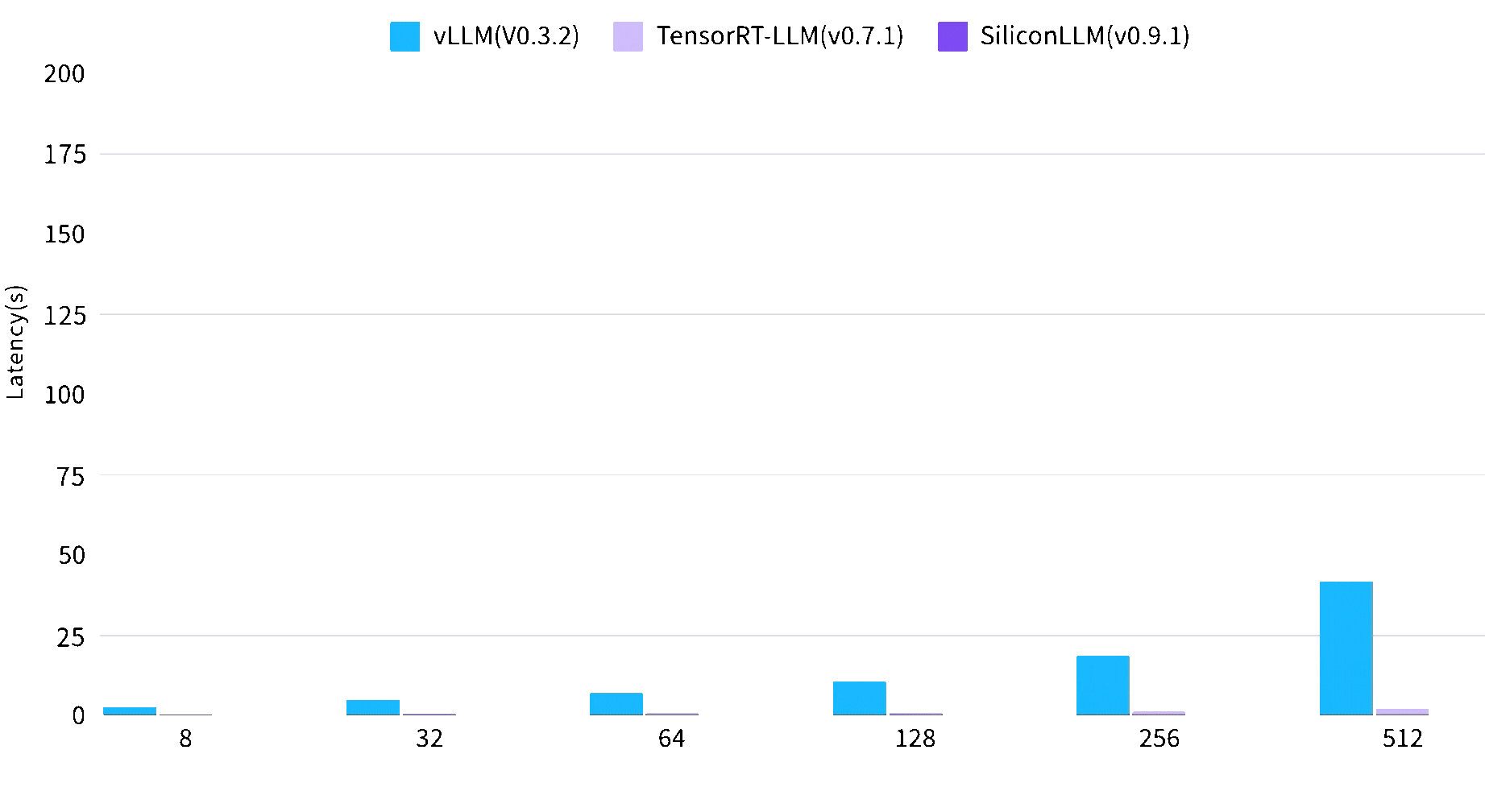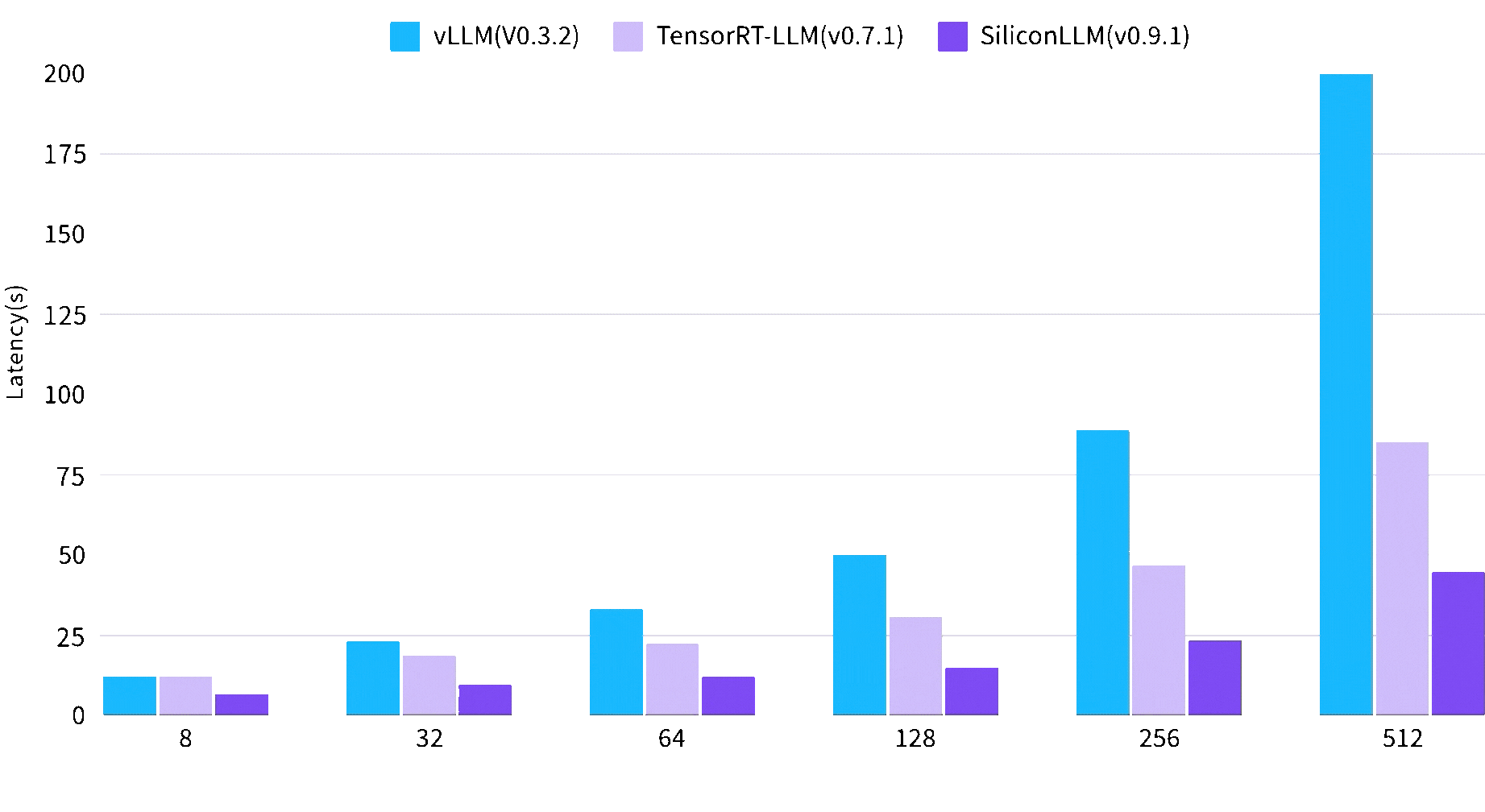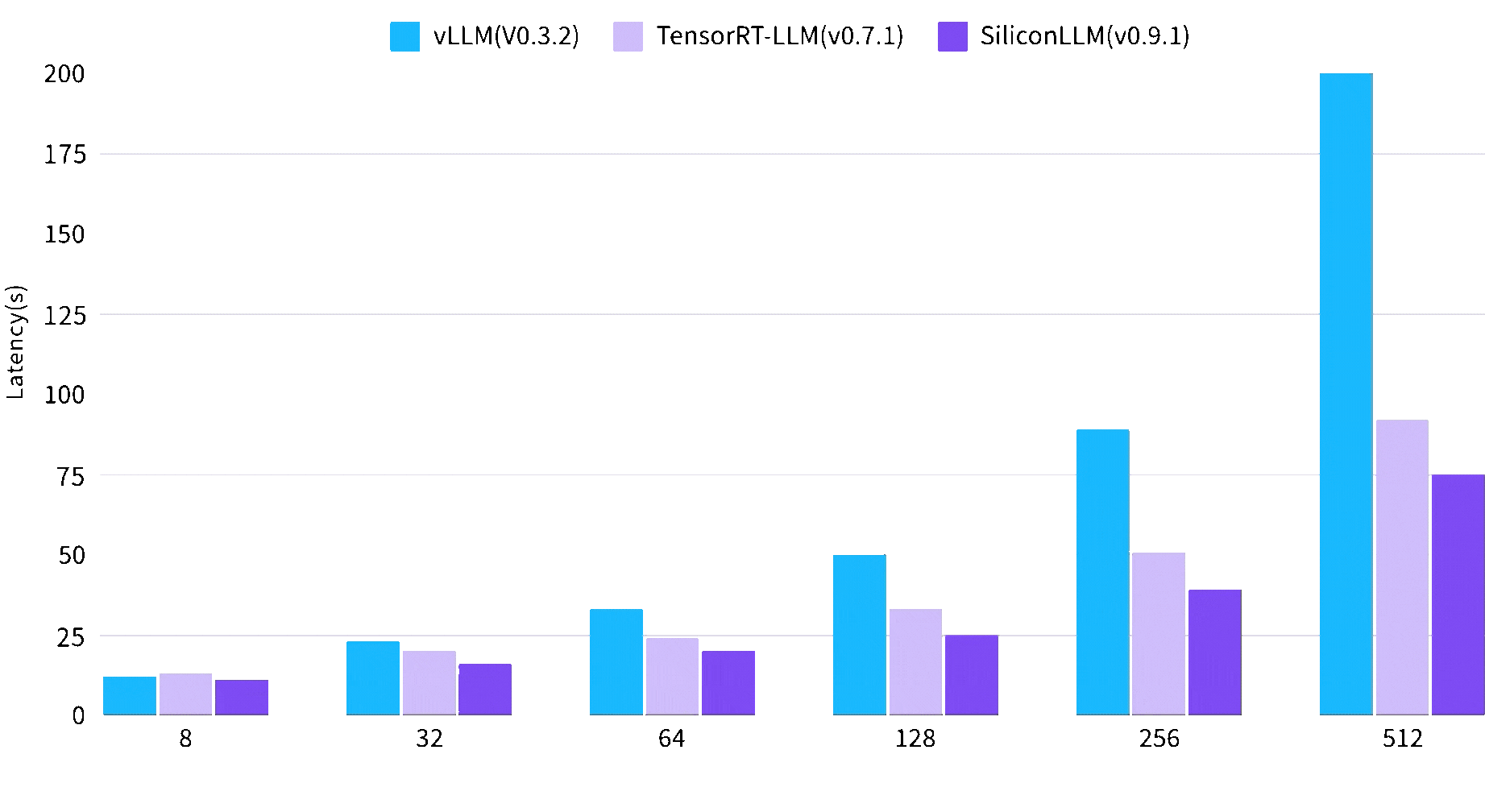
Max Concurrent Requsets
Max Concurrent Requsets
Max Concurrent Requsets
文生图推理速度最快提升3倍
文生图推理速度最快提升3倍
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
Image 1024*1024, batch size, steps 30, on A100 80GB SXM4
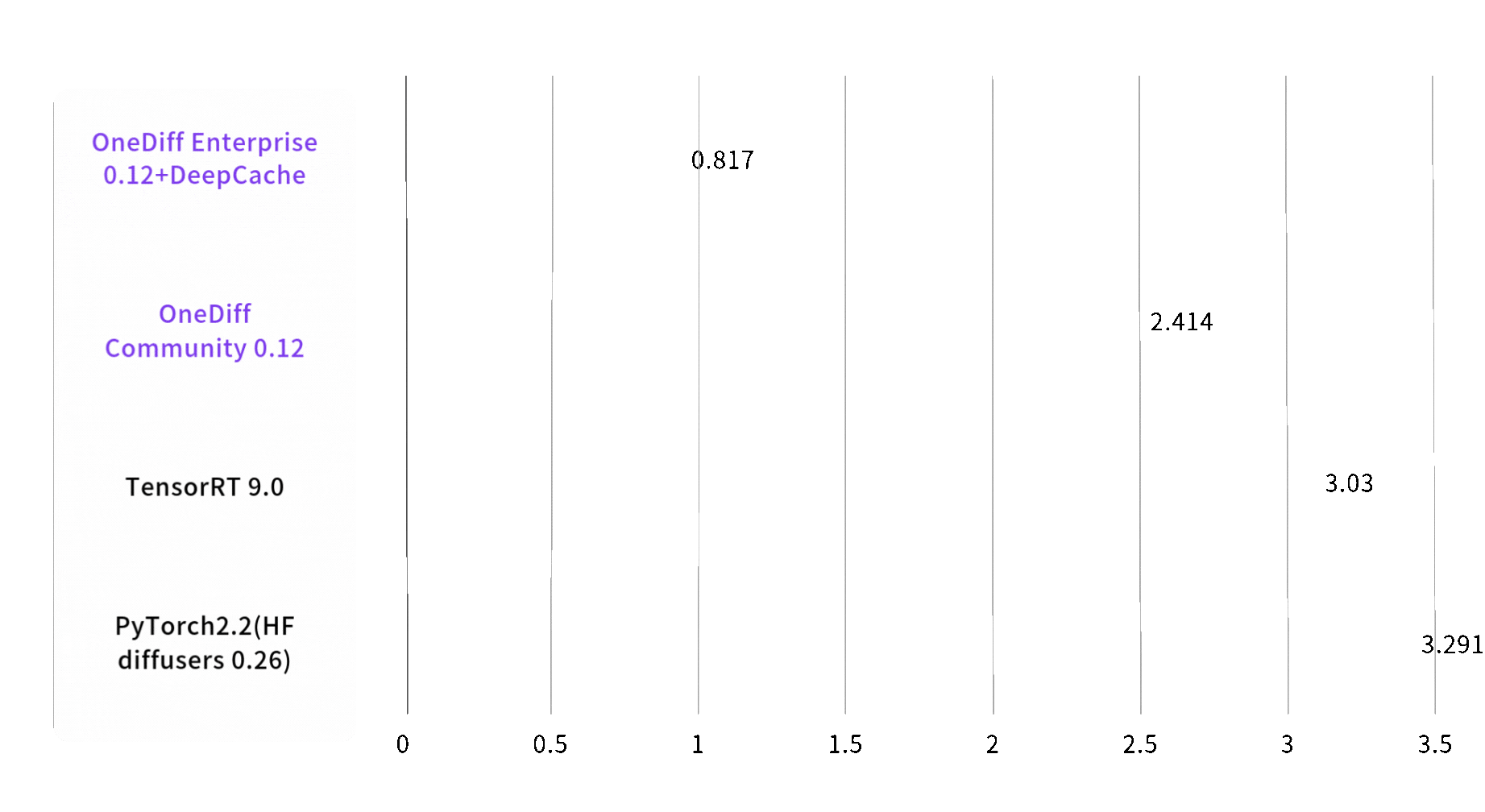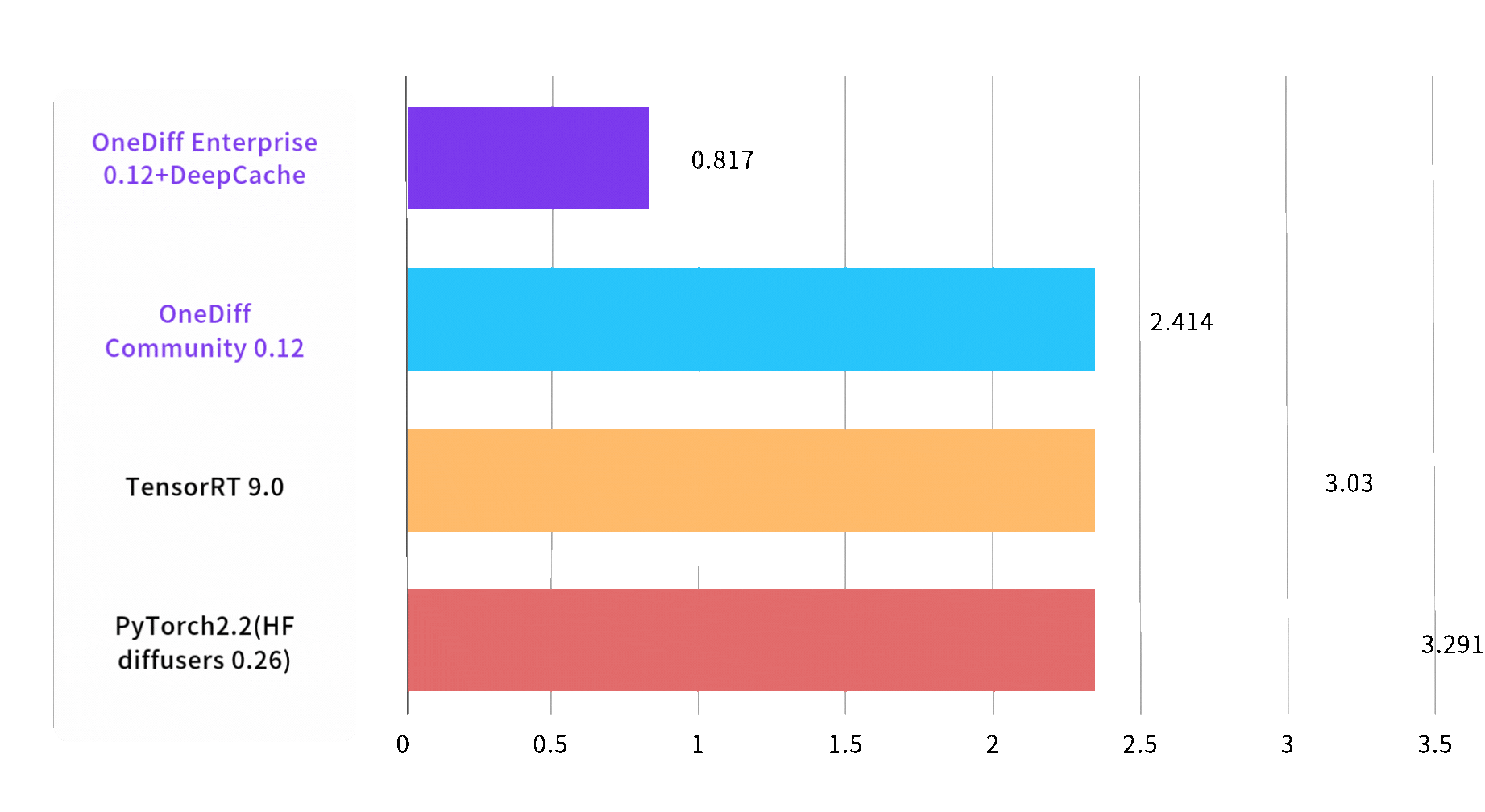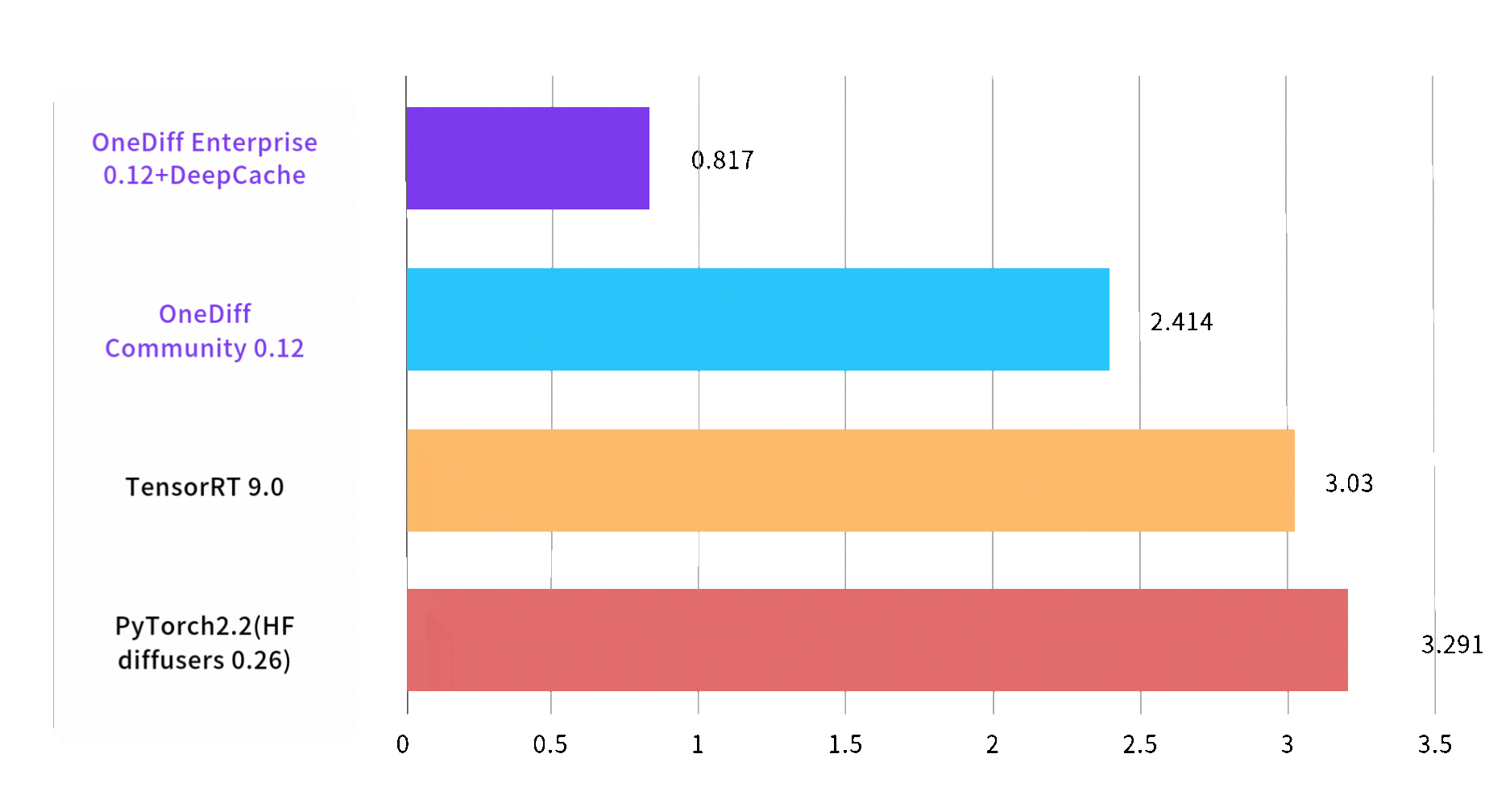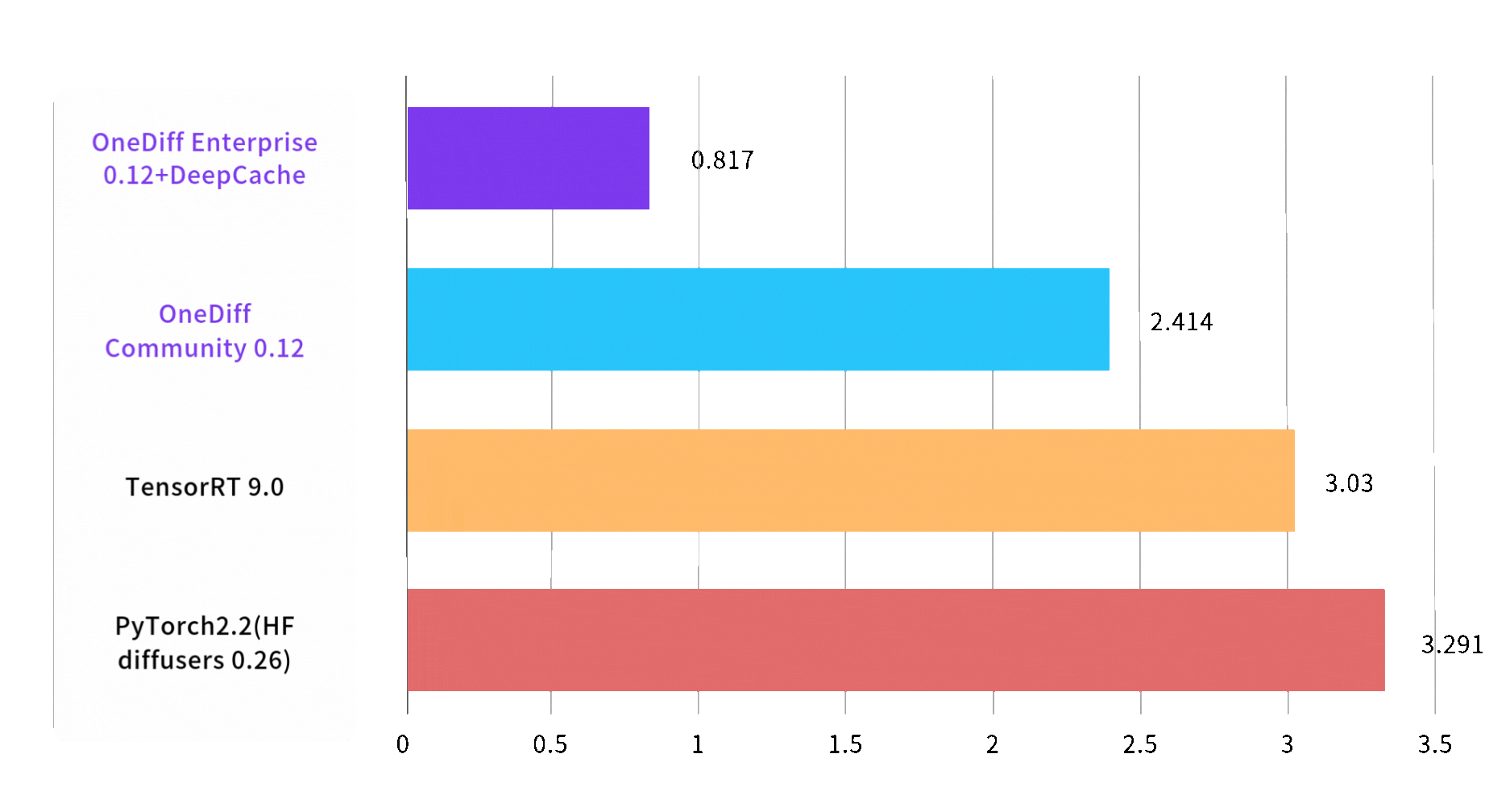
End2End Time (sec)
End2End Time (sec)
End2End Time (sec)
按需自动缩扩容,降低总拥有成本
按需自动缩扩容,降低总拥有成本
按需自动缩扩容,降低总拥有成本
1.
1.
创建包含SiliconFlow实例集合的自动缩扩容组。
创建包含SiliconFlow实例集合的自动缩扩容组。
1.
平台根据配置提供加速效果评估,用户按需选择是否加速。
3.
指定该组中实例数的最大最小值。
2.
指定所需的容量和自动扩展策略。
2.
4.
2.
指定所需的容量和自动扩展策略。
指定所需的容量和自动扩展策略。
创建成功,平台将按需自动调整服务规模,确保在负载高峰时快速扩展实例,负载减少时缩减资源。
3.
3.
指定该组中实例数的最大最小值。
指定该组中实例数的最大最小值。
4.
4.
创建成功,平台将按需自动调整服务规模,确保在负载高峰时快速扩展实例,负载减少时缩减资源。
创建成功,平台将按需自动调整服务规模,确保在负载高峰时快速扩展实例,负载减少时缩减资源。

简单易用
简单易用
简单易用
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
模型推理
只需数行代码,开发者即可快速使用SiliconCloud的快速模型服务。
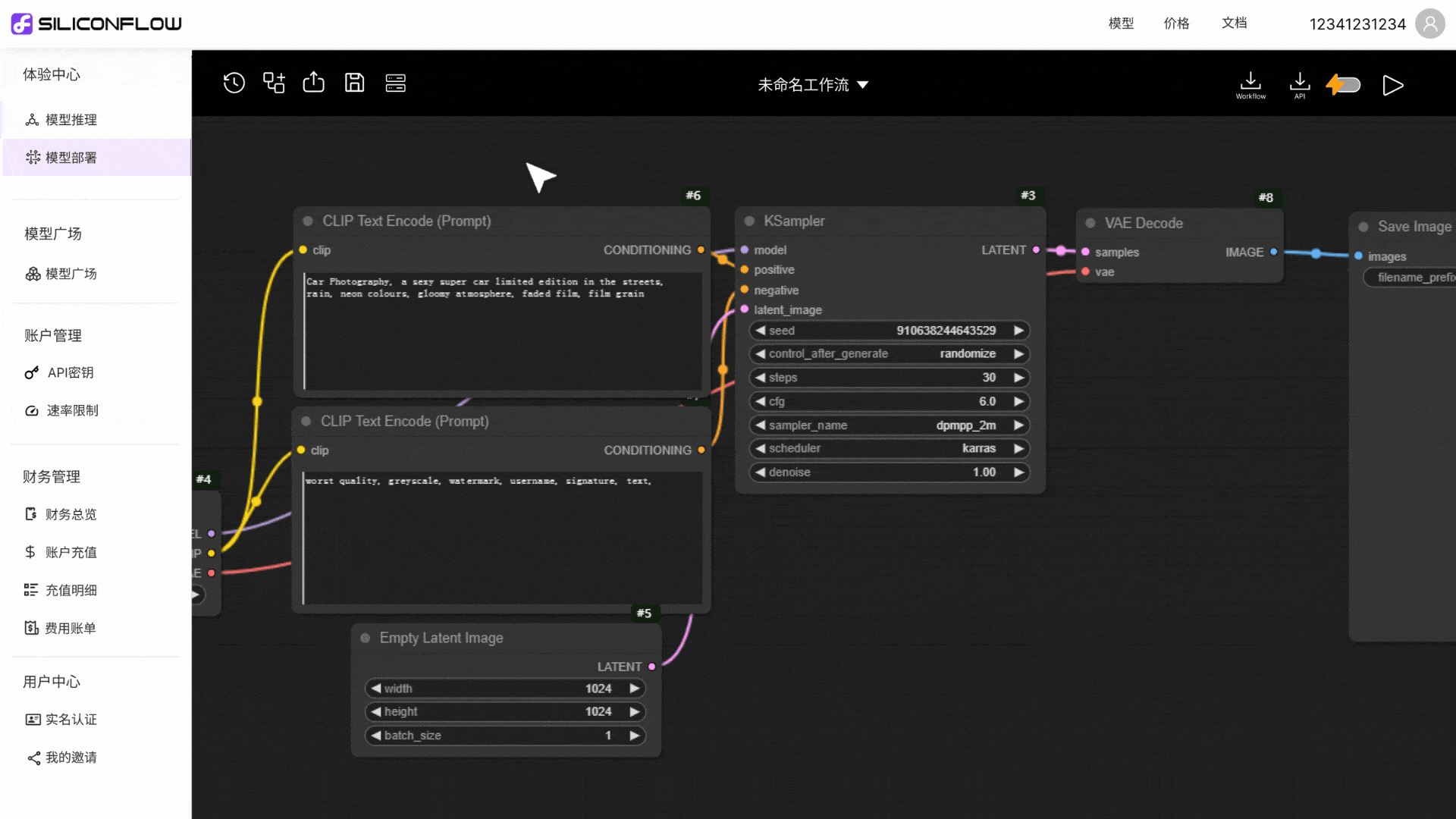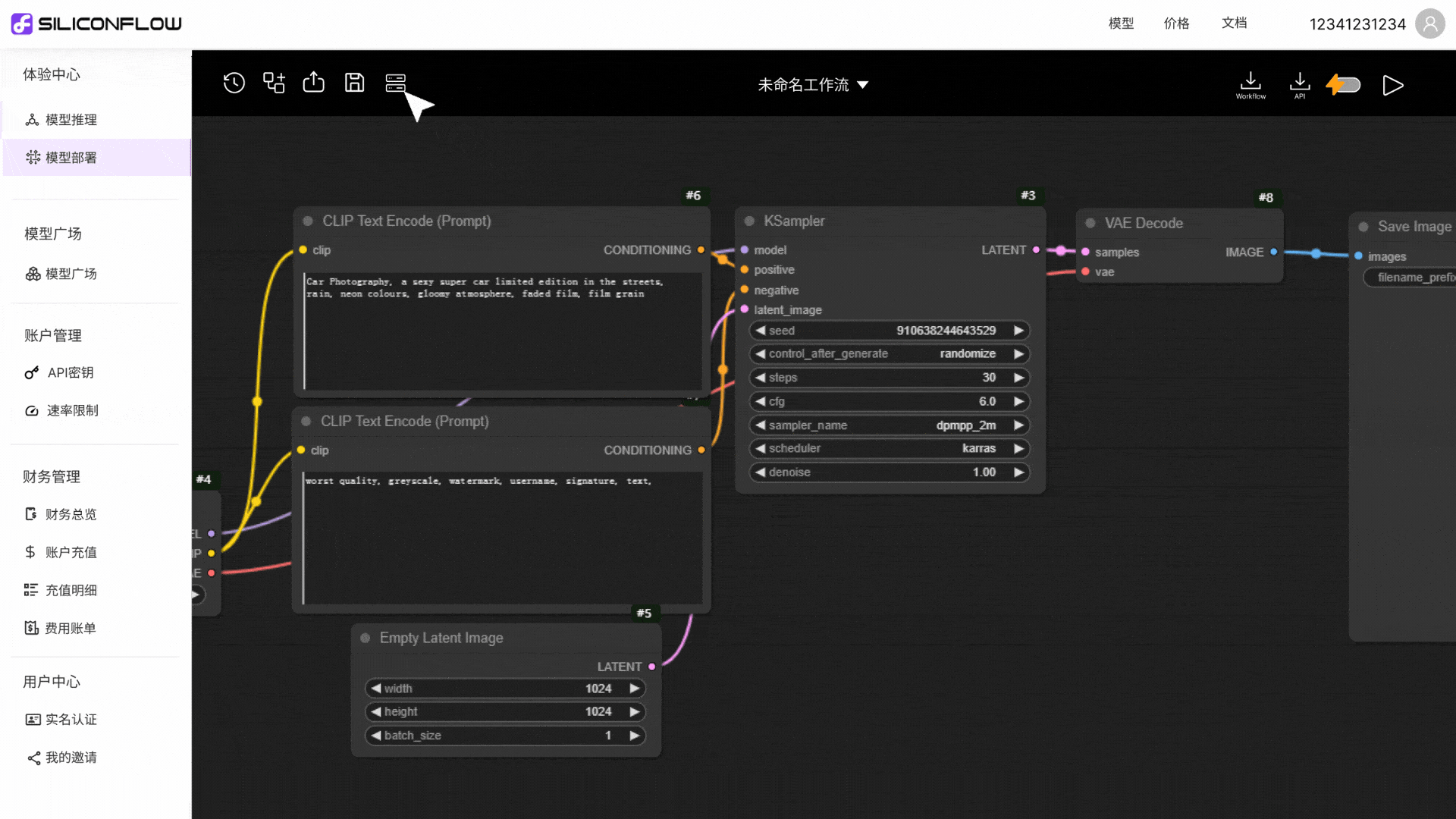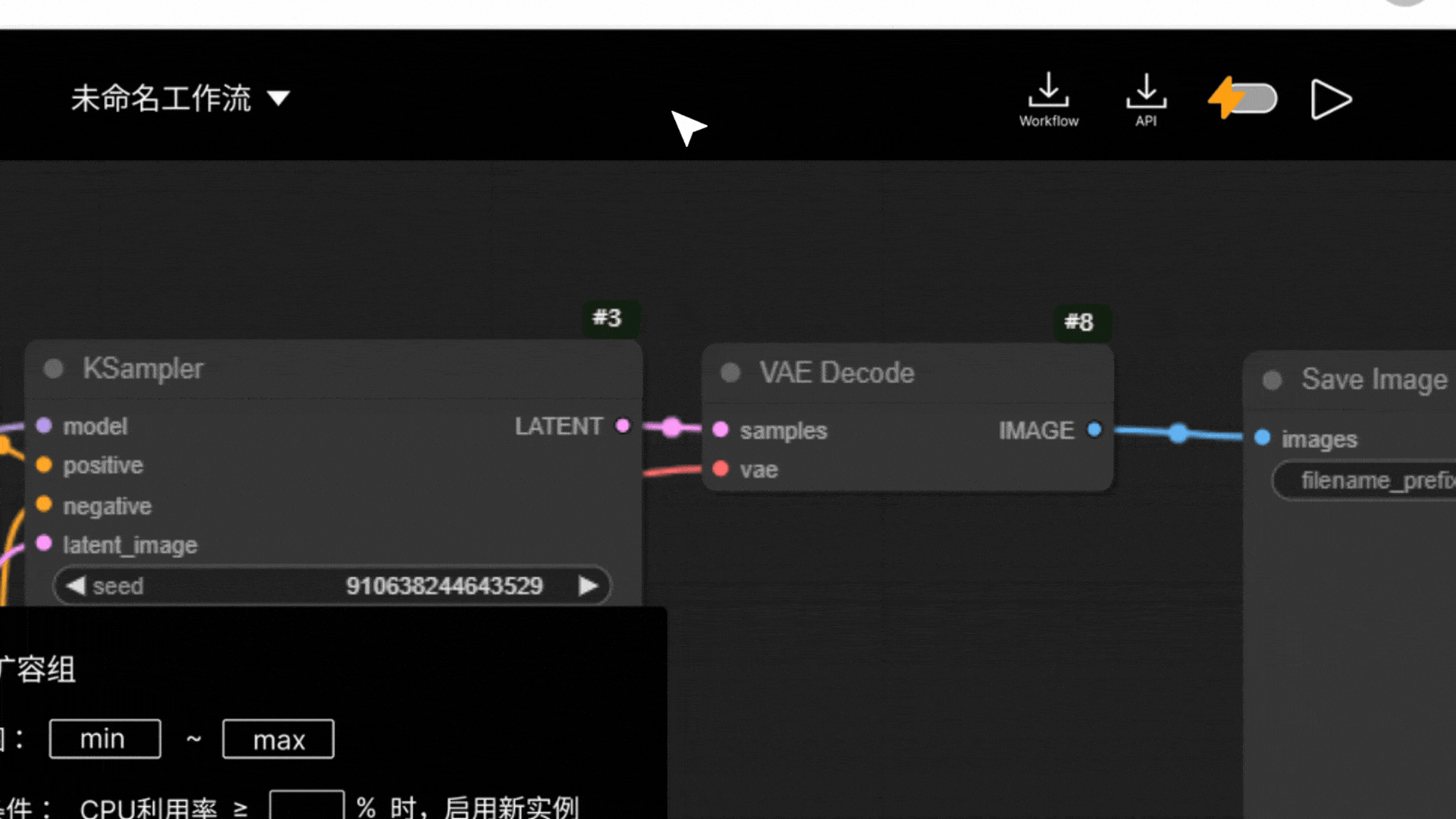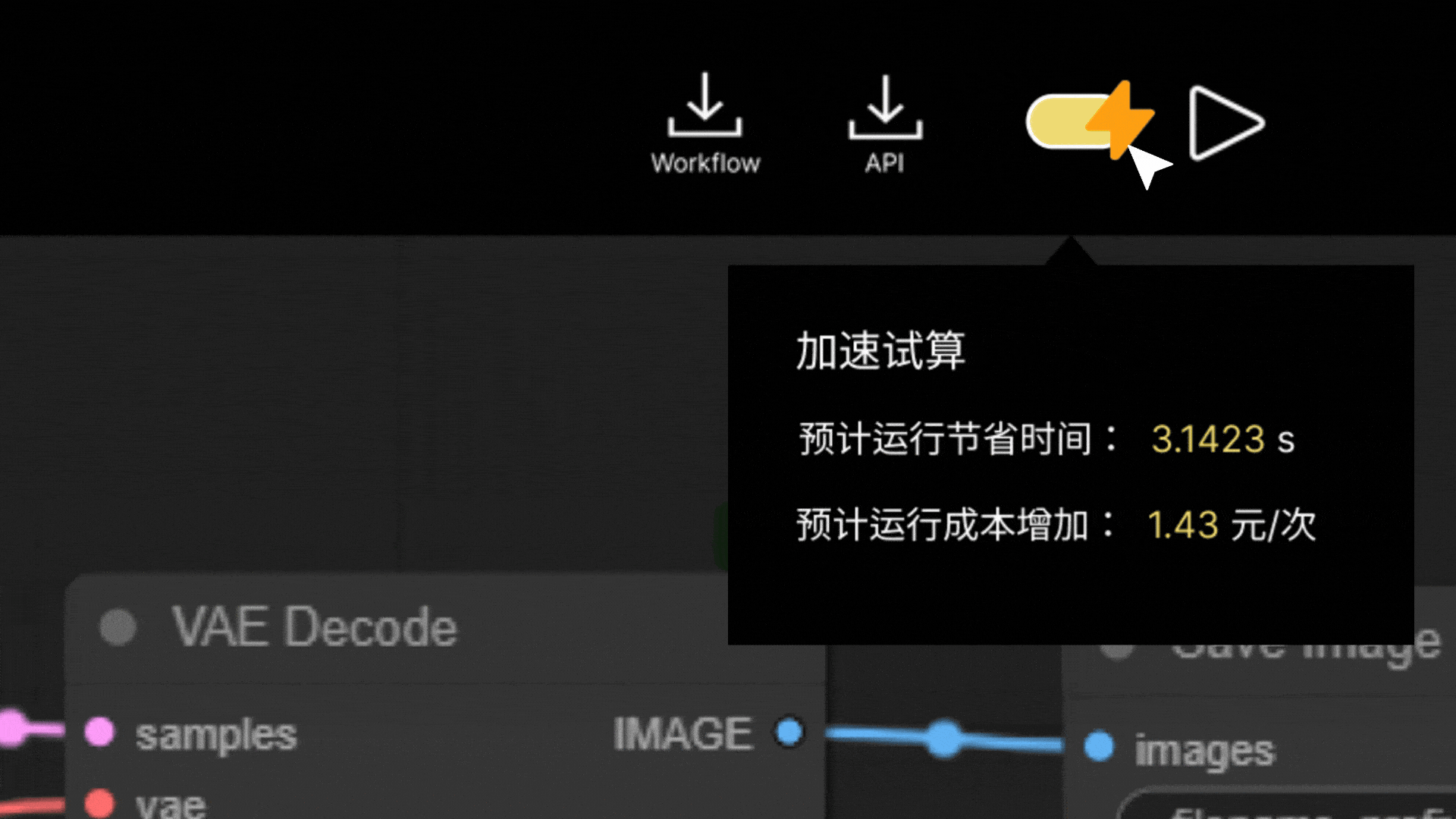
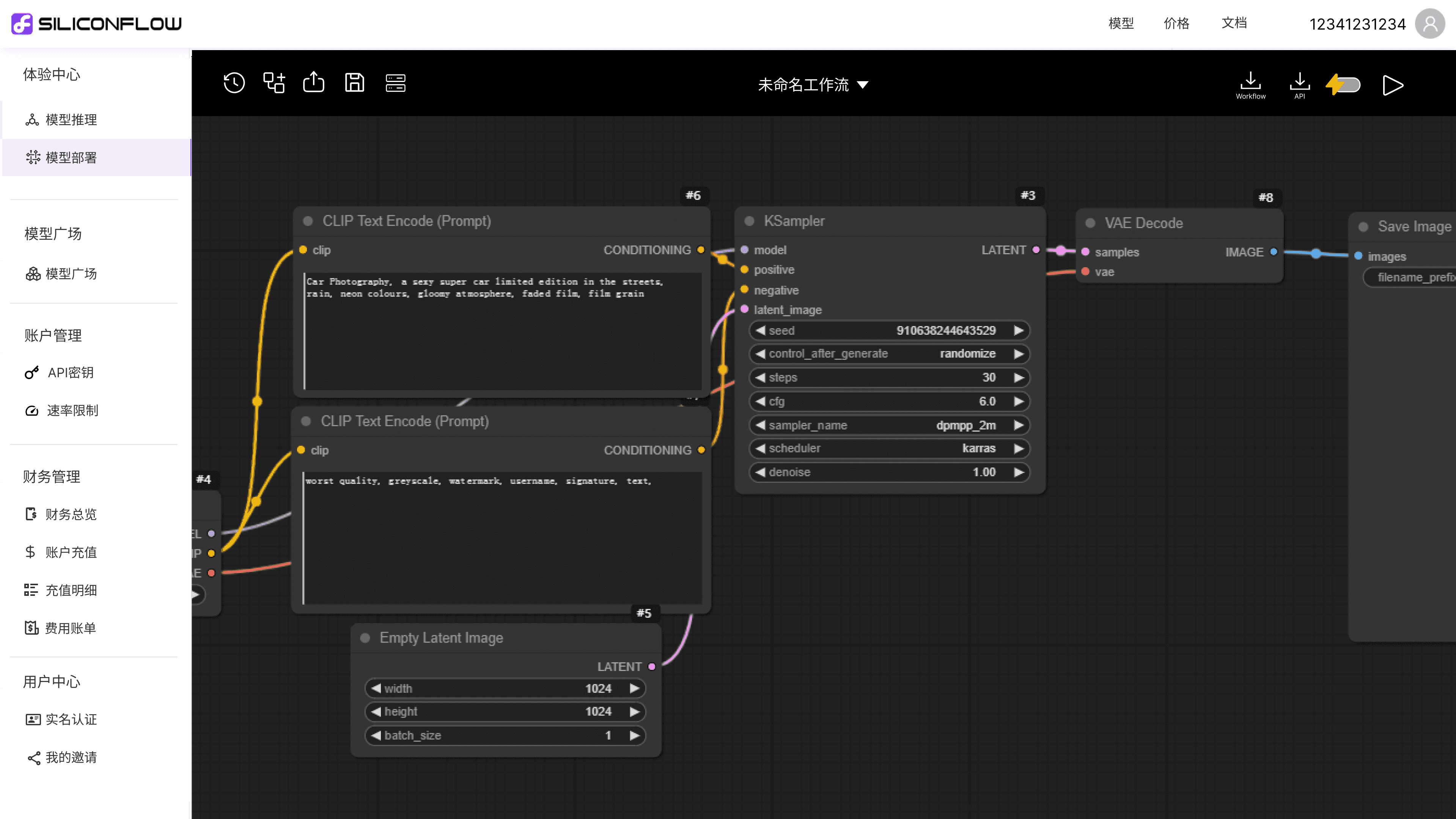
模型部署
·
上传模型服务描述,获取模型服务 API。
·
根据负载自动缩扩容,保持资源最优化。
·
平台根据配置提供加速效果评估,用户按需选择是否加速。
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-V2.5',
messages=[
{'role': 'user',
'content': "SiliconCloud推出分层速率方案与免费模型RPM提升10倍,对于整个大模型应用领域带来哪些改变?"}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
模型推理
模型推理
只需数行代码,开发者即可快速使用SiliconCloud的快速模型服务。
只需数行代码,开发者即可快速使用SiliconCloud的快速模型服务。
模型部署
模型部署
·
上传模型服务描述,获取模型服务 API。
上传模型服务描述,获取模型服务 API。
·
根据负载自动缩扩容,保持资源最优化。
根据负载自动缩扩容,保持资源最优化。
·
平台根据配置提供加速效果评估,用户按需选择是否加速。
平台根据配置提供加速效果评估,用户按需选择是否加速。
服务模式
服务模式

关注硅基流动微信公众号

扫小助理进入用户群